[DB] 데이터베이스와 데이터베이스 시스템
기본적인 개념과 특징, 구성에 대하여
Data, Information, Knowledge
- Data: 관찰의 결과로 나타난 정량적, 혹은 정성적인 실제 값
- Information: 데이터에 의미를 부여한 것
- Knowledge: 사물이나 현상에 대한 이해
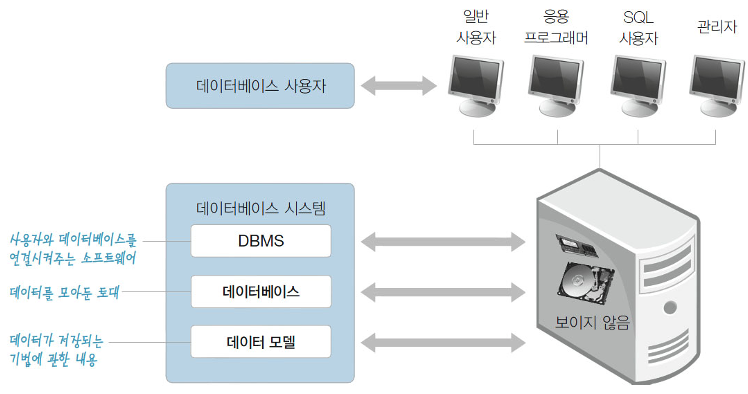
Database
- 정의
- 조직에 필요한 정보를 얻기 위해 논리적으로 연관된 데이터를 모아 구조적으로 통합해 놓은 것
- 개념
- Integrated data: 데이터를 통합하는 개념. 각자 사용하던 데이터의 중복 최소화, 중복으로 인한 데이터 불일치 현상 제거
- Stored data: 문서로 보관된 데이터가 아닌 디스크, 테이프 같은 컴퓨터 저장장치에 저장된 데이터
- Operational data: 조직의 목적을 위해 사용되는 데이터. 즉 업무를 위한 검색의 목적으로 저장된 데이터
- Shared data: 한 사람/업무를 위해 사용되는 데이터가 아닌 공동으로 사용되는 데이터
- 특징
- Real-time accessibility: 실시간으로 접근 가능. 데이터 요청 시 수 초 내에 결과 제공
- Continuous change: 시간에 따라 항상 바뀜.
- Concurrent sharing: 서로 다른 업무, 여러 사용자에게 동시 공유.
- Reference by content: 실제 데이터의 물리적 위치가 아닌, 데이터 값에 따라 참조
- 구성
Growth of Information System
- File System
- 데이터를 파일 단위로 파일 서버에 저장
- LAN을 통해 파일 서버에 연결, 파일 서버에 저장된 데이터 사용을 위해 각 컴퓨터의 응용 프로그램에서 open/close를 요청
- 각 응용 프로그램이 독립적으로 파일을 다룸 → 데이터 중복 저장 가능성 존재
- 동시에 파일을 다룸 → 데이터 일관성 훼손 가능성 존재
- Database System
- DBMS 도입, 데이터 통합 관리
- DBMS가 설치되어 데이터를 가진 쪽은 Server, 외부에서 데이터를 요청하는 쪽은 Client
- DBMS Server가 파일을 다룸 → 데이터 일관성 유지, 복구, 동시 접근 제어. 중복 최소화 및 무결성 유지
- Web Database System
- Database를 Web browser에서 사용할 수 있도록 함
- 불특정 다수 고객을 상대로 하는 Online 상거래, 공공 민원 서비스 등
- Distributed Database System
- 여러 곳에 분산된 DBMS Server를 연결하여 운영
- 대규모의 응용 시스템에 사용
To Save Data,
책들의 정보를 저장한다고 가정하자
-
Saving inside a program
- C언어 structure BOOK 선언 후 main( )에서 structure array 변수 BOOKS[ ] 내부에 data 저장
- 문제는 new data마다 program 수정 후 re-compile이 필요하다는 것
- 코드를 작성해보면 아래와 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31/* BOOK 데이터 구조 정의 */ typedef struct { int bookid[5]; char bookname[20]; char publisher[20]; int price; } BOOK; int main() { BOOK BOOKS[10]; /* 구조체 배열 변수에 데이터 저장 */ /* 첫 번째 도서 저장 */ BOOKS[1].bookid=1; strcpy(BOOKS[1].bookname, "C Programming"); strcpy(BOOKS[1].publisher, "오렌지미디어"); BOOKS[1].price=7000; /* 두 번째 도서 저장 */ BOOKS[2].bookid=2; strcpy(BOOKS[2].bookname, "명품 Java"); strcpy(BOOKS[2].publisher, "한빛"); BOOKS[2].price=13000; /* 나머지 다른 도서 저장(생략) */ ..... /* 모든 도서보기 프로그램 호출 */ search_all(); ..... } -
Using file system
-
BOOK data structure 선언 후 main( )에서 file로부터 data를 불러와 BOOKS[ ]에 저장
fp = fopen("book.dat", "rb");등 read method 사용 - new data마다 program 수정은 불필요하나, 같은 file을 두 program이 공유하는 것이 O/S의 도움 없이 불가능
book.dat라는 파일이 있다는 가정 하에 코드를 작성해보면 아래와 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30/* BOOK 데이터 구조 정의 */ typedef struct { int bookid[5]; char bookname[20]; char publisher[20]; int price; } BOOK; int main( ) { BOOK BOOKS[10]; int i=1; /* 도서 입력 함수 */ insert( ); /* 파일에 저장된 데이터를 배열 BOOKS[ ]에 저장 */ fp=fopen("book.dat","rb"); bp=(BOOK*)calloc(1,sizeof(BOOK)); /* 파일에서 책을 읽는다 */ while(fread(bp,sizeof(BOOK),1,fp) != 0){ BOOKS[i].bookid = bp->bookid; strcpy(BOOKS[i].bookname, bp->bookname); strcpy(BOOKS[i].publisher, bp->publisher); BOOKS[i].price = bp ->price; i++; } /* 모든 도서보기 프로그램 호출 */ search_all( ); ..... } -
-
Using DBMS
- data definition, value를 DBMS가 관리
- program에 data 정의, 값들을 포함하지 않기 때문에 data structure가 바뀌어도 re-compile 불필요
- MySQL을 사용한 database가 있다는 가정 하에 코드를 작성하면 아래와 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26int main( ) { /* 반환된 행의 수 */ int num_ret; /* DBMS에 접속 */ EXEC SQL CONNECT :username IDENTIFIED BY :password; /* SQL 문 실행 */ EXEC SQL DECLARE c1 CURSOR FOR SELECT bookname, publisher, price FROM BOOK; EXEC SQL OPEN c1; /* 모든 도서보기 프로그램 호출 */ search_all( ); /* SQL 문 실행 결과 출력 */ for (;;) { EXEC SQL FETCH c1 INTO :BOOK_rec; print_rows(num_ret); } EXEC SQL CLOSE c1; /* 접속 해제 */ EXEC SQL COMMIT WORK RELEASE; }
결론적으로 database가 아주 중요하다는 거다. 정리해보자
Advantages of DBMS
| 구분 | File System | DBMS |
|---|---|---|
| data 중복 | data를 file 단위로 저장 → 중복 가능 | DBMS를 통해 데이터 공유 → 중복 가능성 낮음 |
| data 일관성 | data 중복 저장 → 일관성 결여 | 중복 제거 → 데이터 일관성 유지 |
| data 독립성 | data 정의, 프로그램 독립성 유지 불가 | data 정의, 프로그램 독립성 유지 가능 |
| 관리 기능 | 보통 | data 복구, 보안, 동시성 제어 등 관리 수행 |
| 생산성 | 나쁨 | 짧은 시간에 큰 프로그램 개발 가능 |
| 기타 장점 | 별도SW 설치 불필요 (OS가 지원) | 데이터 무결성 유지, 데이터 표준 준수 용이 |