[ML] 사이킷런에 관하여
Week#4 / Video / Reference: Prof.Choi
Scikit-Learn
Scikit-Learn은 Machine Learning을 위한 open-library중 하나로, 다양한 기계 학습 Algorithm을 구현한 python library이다. Simple하고 일관성 있는 API, 유용한 online document, 풍부한 예제를 통해 ML을 위한 쉽고 효율적인 library를 제공한다. 또한 개발을 위한 framework와 API를 제공하며, 많은 사람들이 사용함으로써 다양한 환경에서 검증된 library이다. 본 사이트에서 제공하는 요소들 몇 개를 뽑아보자면 다음과 같다.
- Classification 분류
- Regression 회귀
- Clustering 클러스터 분석
- Semi-Supervised Learning 준 지도 학습
- Feature Selection 특징 선택
- Feature Extraction 특징 추출
- Manifold Learning 매니폴드 학습
- Dimensionality Reduction 차원 축소
- Kernel Approximation 커널 근사
- Hyperparameter Optimization 하이퍼파라미터 최적화
- Evaluation Metrics 평가 지표
- Out-of-core Learning … 등
Module
지금까지 공부한 Data Stucture, Algorithm 등의 학문은 low-level programming, 직접 코드를 짜는 방법을 익혔다면 Machine Learning에서는 직접 코딩하는 것보다 higher level에서 modules를 호출하는 방식으로 공부한다. Scikit-Learn에는 다음과 같은 모듈들이 존재한다.
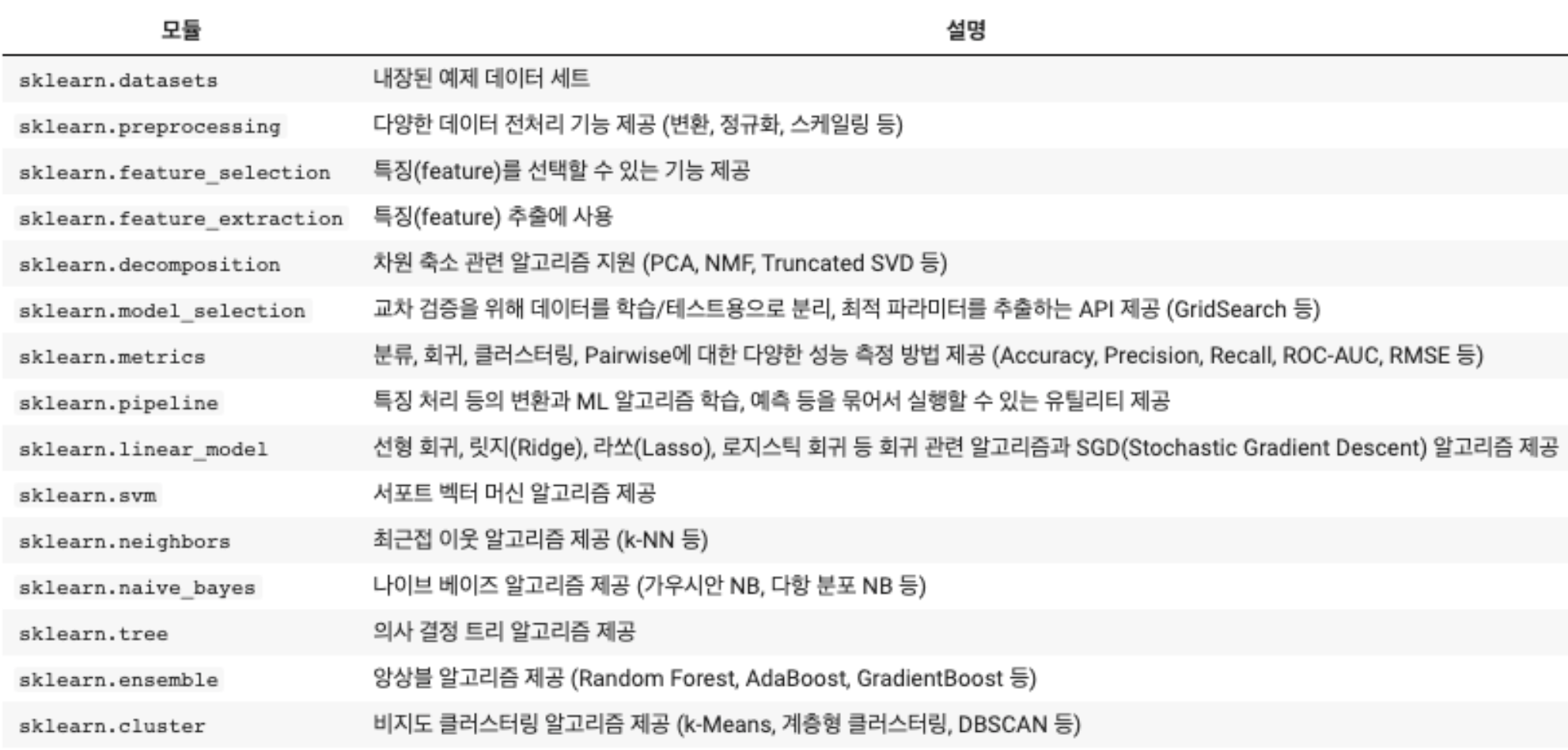
Manual
수많은 open source가 존재하는 현 시대에 가장 필요한 능력은 바로 manual을 찾아보는 것이다. 누군가 가르쳐 주지 않아도 직접 찾아보고, 사용법을 익히는 연습을 해야 할 것이다.
Estimator API
Scikit-Learn에는 estimator라는 개념이 존재한다. 이는 앞서 설명했던 기계학습 문제를 풀기 위한 방법론들을 호출하기 위한 기능을 제공하는 형태이다. 다음과 같은 특징을 가진다.
-
일관성: 모든 객체는 일관된 문서를 갖춘 제한된 method 집합에서 비롯된 공동 interface를 공유한다.
만약 모든 방법론마다 호출 방법, 함수 명이 다르면 기억하기가 매우 힘들 것이다. (fit 등)
-
제한된 객체 계층 구조: Algorithm만 python class에 의해 표현되고, dataset은 standard format으로 표현된다.
Numpy, Pandas dataframe, Scipy 희소 행렬 등이 표준 format이다.
-
합리벅인 기본 값: model이 user-defined parameter를 필요로 할 때 library가 적절한 기본 값을 정의한다.
API 사용 방법
API는 우리가 호출해야 할 대상이다. 다음과 같은 사용 방법이 존재한다.
-
Scikit-Learn에서 적절한 estimator class를 import해서 model의 class 선택
-
class를 원하는 값으로 instance화 해서 hyper-parameter 선택
-
data를 특징 array와 대상 vertor로 배치
-
model instance의 fit() method를 호출해 data에 적합
-
model을 새 data에 대해 적용
-
지도학습: 알려지지 않은 data에 대한 label 예측
대체로 predict() method 사용
-
비지도학습: data 속성을 변환하거나 추론
대체로 transform(), predict() method 사용
-