[ML] KNN을 활용한 분류 문제
Week#5-2 / Video / Reference: Prof.Choi
Machine learning의 일반적인 실습 순서는 다음과 같다.
- Dataset 불러오기
- Category type인 경우 실수화
- 데이터 분할
- 입력 데이터의 표준화 (option)
- 모형 추정 혹은 사례중심학습
- 결과 분석
Overview
재배환경 별 작물 종류 예측
본 데이터셋은 환경에 따른 추천 작물 서비스를 위한 데이터셋이며, 세종대학교 최유경 교수님의 재배환경 별 작물 종류 예측 competition를 출처로 둔다.
Description
이상 기후, 온난화등의 문제로 기상 변화 문제로 농업의 생태계는 다양한 변화를 맞이하고 있다. 기후를 통제하여 안정적인 생산력을 유지하는 Smart-Farm과 더불어 변화하는 환경에 맞추어 적절한 작물을 찾는 시도도 필요하며, 본 과제를 통해 이러한 요구를 해결하고자 한다. 데이터는 다음의 정보를 포함한다.
- N - 토양 내 질소 함량 비율
- P - 토양 내 인산 함량 비율
- K - 토양 내 칼륨 함량 비율
- temperature - 섭씨 온도
- humidity - 상대 습도(%)
- ph - 토양의 ph 값
- rainfall - 강우량 (mm)
주어진 환경정보를 통해 환경에 적합한 작물을 예측해보자.
Preparation
지난 포스팅에서 소개했듯, Colab을 이용하여 개발 환경을 세팅한다.
-
kaggle install
1
2
3!pip uninstall -y kaggle !pip install --upgrade pip !pip install kaggle==1.5.6 -
API token upload
1
2
3!mkdir -p ~/.kaggle !cp kaggle.json ~/.kaggle/ !chmod 600 ~/.kaggle/kaggle.json -
Import libraries
1
2import numpy as np import pandas as pd
Data Loading
문제에 대한 이해가 끝나면 먼저 competition의 Data 탭에서 필요한 데이터를 가져온다.
-
Import dataset from Kaggle
1
2!kaggle competitions download -c 2021-ml-p3 !unzip 2021-ml-p3.zip -
Input data
1
2
3
4
5crops = pd.read_csv('train.csv') # file read test = pd.read_csv('test.csv') x = crops.drop(['label'],axis=1) # 'label'열 drop 후 input X로 정의 y = crops['label'] # 'label'열 label Y로 정의
Data Preprocessing
-
Category transforming
1
2
3from sklearn.preprocessing import LabelEncoder # import LabelEncoder() method le = LabelEncoder() y = le.fit_transform(crops['label'].values) # 'label' to num value -
Inverse (기존 문자열로 변환하여 다른 변수에 저장)
1
2yo = le.inverse_transform(y) # 기존 문자열로 변환 print('labels:', np.unique(yo)) -
Data Split (추후 정확도 확인을 위한 train, test set split)
1
2
3
4
5from sklearn.model_selection import train_test_split #Scikit-Learn 의 model_selection library를 train_test_split로 명명 x_train,x_test,y_train,y_test = train_test_split(x,y, test_size=0.3, random_state=1, stratify=y) # x, y의 data를 test_set(30%)과 training_set(70%)으로 나눔 -
Standardization
여기서는 StandardScaler를 사용하였지만, 보통 data특성이 bell-shape이거나 이상치가 있지 않은 이상 MinMaxScaler(Normalization) 가 더 유용하다.
1
2
3
4
5from sklearn.preprocessing import StandardScaler sc = StandardScaler() sc.fit(x_train) # x_train에 fit x_sc = sc.transform(x_train) # train data 표준화 x_test_sc = sc.transform(x_test) # test data 표준화 -
Fitting
함수 parameter는 실험적으로 결정한다. 여기서는 n의 개수와 distance metric을 조정해주었다.
1
2
3from sklearn.neighbors import KNeighborsClassifier knc = KNeighborsClassifier(n_neighbors=7, p=1) knc.fit(x_sc, y_train) # model fitting -
Scoring
분류 문제는 회귀 분석과 달리 다양한 성능 평가 기준이 필요하며, 평가 방법마다 장단점이 존재한다.
1
2
3
4
5
6
7y_train_pred = knc.predict(x_sc) # train data의 y값 예측값 y_test_pred = knc.predict(x_test_sc) # 모델을 적용한 test data의 y값 예측값 #test_pred = knc.predict(test_sc) print('Misclassified training samples: %d' %(y_train != y_train_pred).sum()) #오분류 데이터 개수 확인 print('Misclassified test samples: %d' %(y_test != y_test_pred).sum()) #오분류 데이터 개수 확인Misclassified training samples: 20
Misclassified test samples: 131
2from sklearn.metrics import accuracy_score # 정확도 계산을 위한 모듈 import print(accuracy_score(y_test,y_test_pred))0.9737373737373738Scikit-Learn에서 제공하는 분류 성능 평가 방법은 여러가지다. 필자는 첫 번째와 두 번째를 가장 많이 사용한다.
confusion_matrix(y_true, y_pred)혼합 행렬- target의 원래 class와 model이 예측한 class가 일치하는지 개수로 센 결과를 표로 나타냄
accucacy_score(y_true, y_pred)정확도- 전체 sample 중 맞게 예측한 sample 수의 비율
precision_score(y_true, y_pred)정밀도- 특정 class에 속한다고 예측한 sample 중 실제로 해당 class에 속하는 sample 수의 비율
recall_score(y_true, y_pred)재현율- 특정 class에 실제로 속한 sample 중에 해당 class에 속한다고 예측한 sample 수의 비율
fbeta_score(y_true, y_pred, beta)f1_score(y_true, y_pred)roc_curveauc
-
Comparing
혹시 몰라서 데이터 표준화가 성능에 긍정적인 영향을 미치는지 테스트해 보았는데 표준화 이전이 성능이 더 좋았다!
1
knc.fit(x_train, y_train)1
2
3
4
5
6y_train_pred = knc.predict(x_train) # train data의 y값 예측값 y_test_pred = knnc.predict(x_test) # 모델을 적용한 test data의 y값 예측값 print('Misclassified x_training samples: %d' %(y_train != y_train_pred).sum()) # 오분류 데이터 개수 확인 print('Misclassified x_test samples: %d' %(y_test != y_test_pred).sum()) # 오분류 데이터 개수 확인Misclassified x_training samples: 11Misclassified x_test samples: 5`1
2from sklearn.metrics import accuracy_score print(accuracy_score(y_test, y_test_pred))0.9818181818181818표준화는 특성 자료의 측정 단위(Scaling)에 영향을 받지 않도록 하는 과정이다. 이때 test data의 표준화는 train data에서 구한 특성변수의 평균과 표준편차를 이용한다. 만약 표준화로 인해 데이터의 분포인 통계적 특성이 깨지면 machine learning의 학습 저하를 가져온다.
이번 문제에서는 표준화된 데이터를 사용한 이전 결과보다 높은 성능을 보이므로 본 문제에서는 데이터 표준화가 오히려 머신러닝의 학습 저하를 가져온다는 결론에 도달했다. 물론 예측해야 할 test data의 특성이 또 조금씩 다를 수 있기 때문에 바로 확신할 수 있는 것은 아니지만, test data의 accuracy를 점검하여 어느 정도 결정할 수 있다.
-
Submission
1
2test_pred = knc.predict(test) # 해당 모델을 통해 test.csv의 y값 예측값 추출 test_pred = le.inverse_transform(test_pred) # 'label' 도메인 속성에 맞게 재 변환1
2submit = pd.read_csv('sample.csv') submit['label'] = test_pred # sample.csv 파일의 label 열을 모두 예측값으로 갱신1
submit.to_csv('testsub1.csv', index=False) # 제출용 sample 파일 저장1
!kaggle competitions submit -c 2021-ml-p3 -f testsub1.csv -m "Message"Message에는 본인이 알아볼 수 있도록 간단하게나마 version control을 해주면 된다. 나는 주로 preprocessing 여부, parameter value 등을 적어준다.
Result
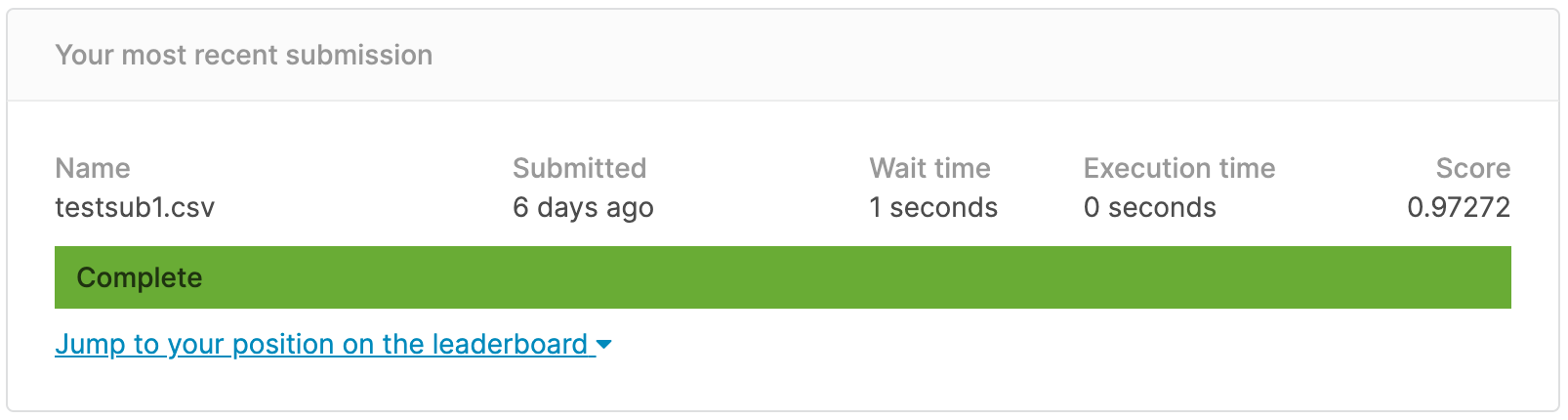
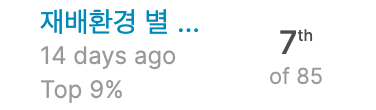
결론적으로 0.97272 의 정확도로 Leaderboard 상에서는 85명 중 7th position까지 올라올 수 있었다 ! 학습 자체도 중요하지만 괜히 생기는 이 경쟁심은… 좋은 의미로 학습에 자극되긴 한다. ( 나쁘게 말하면 과하게 )