[ML] KNN을 활용한 회귀 문제
Week#5-3 / Video / Reference: Prof.Choi
KNN Regression
데이터 가공, scoring 과정 등은 KNN classification과 동일하지만 y의 예측치 계산만 다르다. Regression의 경우 k개 관측치 (𝒙ᵢ, 𝒚ᵢ)에서 ȳ를 계산하여 적합치로 사용한다.
-
단순 회귀: 가까운 이웃들의 단순한 평균을 구하는 방식
-
가중 회귀: 각 이웃이 얼마나 가까이 있는지에 따라 weighted average(가중 평균) 를 구해 거리가 가까울수록 데이터가 더 유사할 것이라고 보고 가중치를 부여하는 방식.
-
ex) 영화 X의 등급을 찾기 위해 3-NN 검색 결과
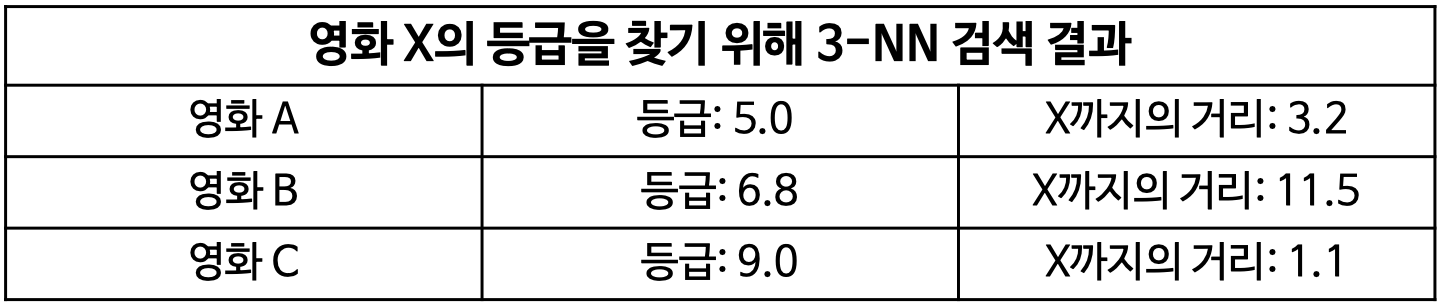
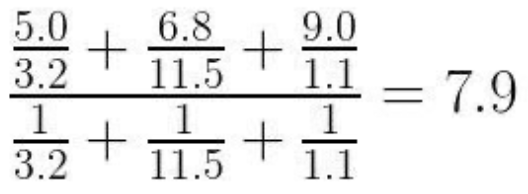
단순 평균은 6.93인데 반해 가중 평균은 7.9이다.
Overview
자동차 가격 예측
본 데이터 셋은 kaggle open dataset으로 영국의 중고차량 정보들로 구성되어있으며, 세종대학교 최유경 교수님의 자동차 가격 예측 competition를 출처로 둔다.
Description
해당 데이터 셋은 중고 차량에 대한 가격, 변속기, 마일리지, 연료 유형, 도로세, 갤런당 마일리지(mpg), 제조회사 및 엔진 크기 등을 포함한다. 위에 언급한 차량의 정보들(제조회사, 엔진크기, 변속기 등)을 통하여 해당 차량의 가격을 예측하는 것이 해당 실습의 목표이다.
- company - 자동차 제조 회사, 총 5개(bmw, ford, hyundai, audi, toyota)의 회사로 구성
- model - 해당 차량의 제품명(모델)
- year - 해당 차량의 제조년도
- transmission - 해당 차량의 변속기
- mileage - 해당 차량의 마일리지
- fueltype - 해당 차량의 연료 유형
- tax - 해당 차량의 세금
- mpg - 해당 차량의 마일 당 갤런 사용량(연비)
- enginesize - 해당 차량의 엔진 크기를 의미
- price - 해당 차량의 가격을 의미합니다.
Data 구성 요소는 위와 같으며, 본 문제의 평가 방식은 MAE(Mean Absolute Error)이다.
즉, Kaggle 채점 결과 값이 낮을수록 더 정확한 모델이라는 것
Preparation
-
kaggle install
1
2
3!pip uninstall -y kaggle !pip install --upgrade pip !pip install kaggle==1.5.6 -
API token upload
1
2
3!mkdir -p ~/.kaggle !cp kaggle.json ~/.kaggle/ !chmod 600 ~/.kaggle/kaggle.json -
Import libraries
1
2import numpy as np import pandas as pd
Data Loading
Competition의 Data 탭에서 필요한 데이터를 가져온다.
-
Import dataset from Kaggle
1
2!kaggle competitions download -c 2021-ml-p6 !unzip 2021-ml-p6.zip -
Input data
1
2
3
4
5
6
7car = pd.read_csv('train_data.csv') # file read test = pd.read_csv('test_data.csv') car = car.drop(['ID'], axis = 1) # 불필요한 'ID'열 제거 test = test.drop(['ID'], axis = 1) x = car.drop(['price'], axis = 1) # 'price'열 drop 후 input X로 정의 y = car['price'] # 'price'열 label Y로 정의
Data Preprocessing
-
Category transforming
1
2
3
4
5from sklearn.preprocessing import LabelEncoder le = LabelEncoder() le.fit(x['model'].tolist()) # x만 fit 시켜주고 print(le.transform(x['model'].tolist())) # transform한 뒤, print(le.transform(test['model'].tolist())) # test는 x의 실수화 경향을 따르도록 한다.[15 87 26 ... 25 33 25]
[44 46 60 ... 46 13 59] -
Inverse (기존 문자열 변환 check)
1
2
3
4x_mod = le.inverse_transform(le.transform(x['model'].tolist())) test_mod = le.inverse_transform(le.transform(test['model'].tolist())) print(x_mod) # check print(test_mod)[' Auris' ' X2' ' Focus' ... ' Fiesta' ' Hilux' ' Fiesta']
[' Ka+' ' Kuga' ' Q5' ... ' Kuga' ' A7' ' Q3'] -
Data Split (정확도 확인을 위한 train, test set split)
1
2
3from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=0, test_size=0.3) -
Standardization
1
2
3
4
5
6
7
8from sklearn.preprocessing import StandardScaler sc = StandardScaler() sc.fit(x) # x에만 fit을 함으로써 다른 데이터들도 경향성을 맞춰준다 x_sc = sc.transform(x) x_train_sc = sc.transform(x_train) x_test_sc = sc.transform(x_test) test_sc = sc.transform(test) -
Fitting for test
앞선 Classification과 마찬가지로 함수 parameter는 실험적으로 결정한다. 아래의 scoring block을 참고하여 여러 번 test하며 n의 개수와 distance metric, weights를 조정해주었다.
1
2
3from sklearn.neighbors import KNeighborsRegressor knr = KNeighborsRegressor(n_neighbors=5, p=1, weights='distance') knr.fit(x_train_sc, y_train) -
Scoring
1
print('{:.4f}'.format(knr.score(x_test_sc, y_test))) # 성능 check0.9480 -
Fitting original / Submission
기존의 unsplited dataset을 다시 학습시켜 test data를 예측한다.
1
knr.fit(x_sc, y)1
pred = knr.predict(test_sc)1
2submit = pd.read_csv('sample_submit.csv') submit['price'] = pred1
submit.to_csv('submit.csv', index = False)1
!kaggle competitions submit -c 2021-ml-p6 -f testsub1.csv -m "Message"
Result
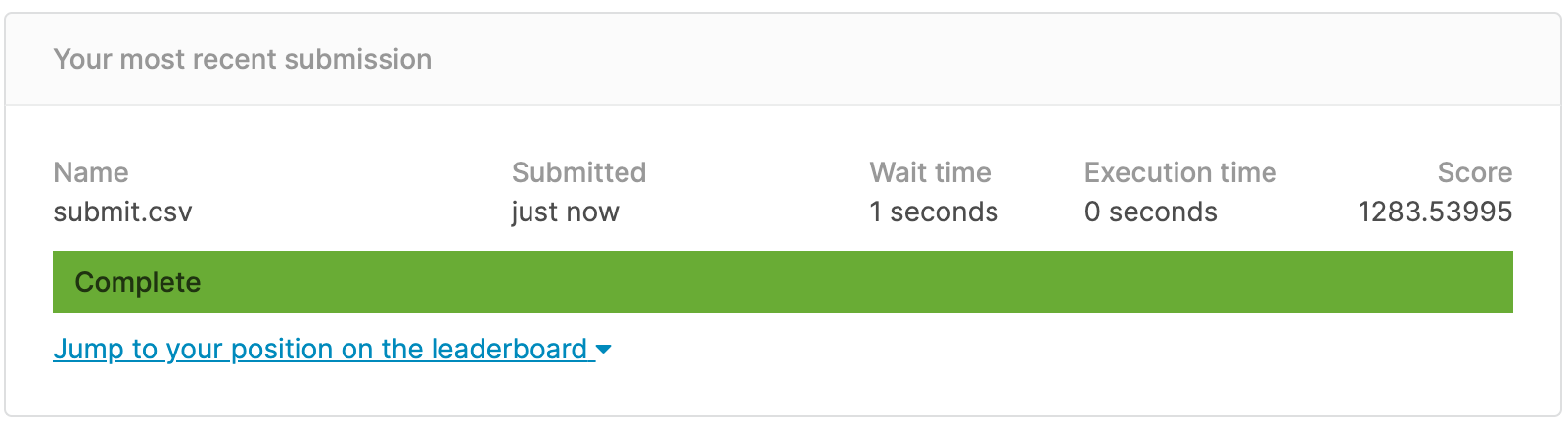
MAE에 따라 1283.53995 정도로 평가되었다. Leaderboard 상에서는 86명 중 13th position정도이다. 아쉽게 deadline 이후에 더 좋은 점수가 나와서 public score에는 반영되지 않았다. ![]()