[ML] LR을 활용한 분류 문제 (2)
Week#6 / Reference: Prof.Choi / based on Colab, Kaggle
Overview
수면 시간에 따른 우울증 예측
본 데이터셋은 다트머스 대학교 학생들에게 수집한 설문조사를 토대로 만들어진 데이터셋이다. 자세한 내용은 링크에서 확인할 수 있으며, 세종대학교 최유경 교수님의 수면 시간에 따른 우울증 예측 kaggle competition를 출처로 둔다.
Description

본 데이터셋은 다트머스대학교 학생들을 대상으로 일정 기간동안 수집한 스마트폰 센서 데이터와 다양한 설문조사 결과를 포함하고 있다. 그 중 본 실습문제에서는 학생들이 응답한 ‘수면시간 및 수면의 질’ 관련 설문조사와 ‘PHQ-9’ 설문조사를 사용할 예정이며, 이를 통해 우울증의 유무를 판단할 예정이다. 본 데이터셋을 제공한 연구팀은 학생들에게 수면과 관련해 다음과 같은 질문을 진행하였다.
- “How many hours did you sleep last night?”
- “How would rate your overall sleep last night?”
위 질문에 대해서 학생들은 설치된 어플리케이션을 통해서 설문조사에 응하였고, 이와 관련된 데이터셋의 자세한 내용은 Student Life Dataset 에서 확인할 수 있다. 본 문제에서는 사전에 설문조사 응답에 대한 전처리를 진행하였고, 학생들의 수면의 시간, 수면의 질에 대한 응답에 대해서 Pandas에서 제공하는 describe 함수를 이용해 feature를 설계하였다.
따라서 추가적인 데이터 전처리 없이 제공되는 Feature를 기존 machine learning 방법을 통해서 학습하고, 평가를 수행하고자 한다. Feature에 대한 자세한 설명은 다음과 같다.
- train_X, test_X : 수면 관련(수면의 양/수면의 질) Feature(14개)
- sleep_time_mean
- sleep_time_std
- sleep_time_min
- sleep_time_25
- sleep_time_50
- sleep_time_75
- sleep_time_max
- sleep_quality_mean
- sleep_quality_std
- sleep_quality_min
- sleep_quality_25
- sleep_quality_50
- sleep_quality_75
- sleep_quality_max
- train_Y : 우울증 유/무를 표기
- 0 : PHQ 9 종합 점수 5점이하
- 1 : PHQ 9 종합 점수 6점이상
- sample_submit : 제출을 위한 양식
Preparation
-
kaggle install
1
2
3!pip uninstall -y kaggle !pip install --upgrade pip !pip install kaggle==1.5.6 -
API token upload
1
2
3!mkdir -p ~/.kaggle !cp kaggle.json ~/.kaggle/ !chmod 600 ~/.kaggle/kaggle.json -
Import libraries
1
2import numpy as np import pandas as pd
Data Loading
Competition의 Data 탭에서 필요한 데이터를 가져온다.
-
Import dataset from Kaggle
1
2!kaggle competitions download -c 2021-ml-p8 !unzip 2021-ml-p8.zip -
Input data
1
2
3X = pd.read_csv('train_X.csv') y = pd.read_csv('train_Y.csv') test = pd.read_csv('test_X.csv')1
2
3
4# pandas to numpy X = X.to_numpy() y = y.to_numpy() test = test.to_numpy()
Data Modeling
-
Fitting
앞선 포스팅과 마찬가지로 Logistic regression을 사용하기 때문에, 함수 parameter 조절을 통해 다양한 규제강도에 따른 실험을 해 보았다. 관련 내용은 한번 더 메모한다.
- L₁, L₂ 규제화
- C = 1/𝜆 를 통한 규제화
- Test data의 label을 알 수 없을 경우, train data 일부를 validation data로 구성하여 test
규제강도가 클수록 추정된 계수들의 절대값이 작아진다. L₁ 규제화의 경우 규제 강도가 클수록 “Sparce”, 계수에 0이 많아진다. 즉, 계수에 대응하는 특성변수를 제거하는 역할을 담당한다고 볼 수 있다.
하지만 이번 코드에서는 이전처럼 C 값을 조절하며 정확도를 향상시키는 것이 아닌,
class_weightparameter를 건드려 보았다. y label data를 보면 0값이 1값보다 눈에 띄게 많은 것을 알 수 있다. 이는 결국 data imbalance를 초래하는 것이기 때문에,class_weightparameter의 value를'balanced'로 지정해 주었다.1
2
3
4
5from sklearn.linear_model import LogisticRegression lr = LogisticRegression(class_weight='balanced') lr.fit(X, y.reshape(-1)) # y vector를 flatten 시켜주는 과정 result = lr.predict(test) -
Submission
1
2submit = pd.read_csv('sample_submit.csv') submit['label'] = result1
submit.to_csv('submit.csv',index=False)1
!kaggle competitions submit -c 2021-ml-p8 -f submit.csv -m "Message"
Result
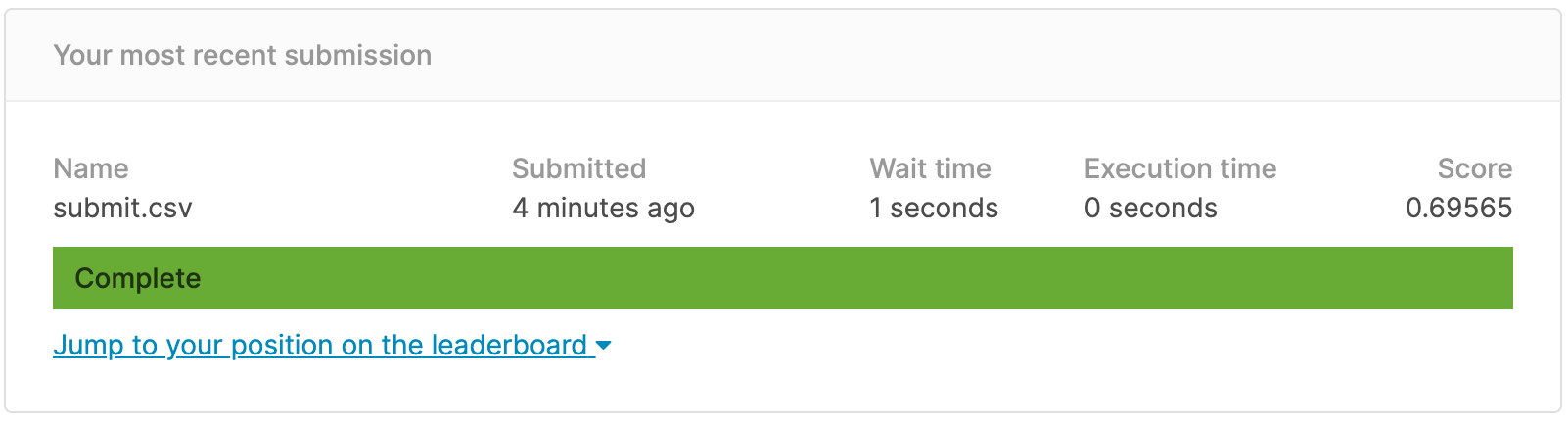
문제를 풀어 나가고 모델을 학습 시키며 성능을 높이는 과정에서 official manual을 적절히 참고하는 것이 얼마나 중요한 것인지 뼈저리게 느낀다. Scikit-learn 뿐만 아니라 pandas, numpy, seaborn, matplotlib 등 수많은 library들의 official documents는 그냥 만들어 둔게 아닐 것이다. 보라고 만들어 둔 거다. 보라고~!