[ML] QDA을 활용한 분류 문제
Week#7 / Reference: Prof.Choi / based on Colab, Kaggle
Overview
당뇨병 환자 예측
본 문제는 주어진 데이터를 이용하여 당뇨병이면 1, 당뇨병이 아니면 0으로 라벨링하는 문제이며, 세종대학교 최유경 교수님의 당뇨병 환자 예측 kaggle competition를 출처로 둔다.
Description
-
Data
- Pregnancies : 임신 횟수
- Glucose : 글루코오스(탄수화물 화합물)
- BloodPressure : 혈압
- SkinThickness : 피부 두께
- Insulin : 인슐린 수치
- BMI : BMI 지수
- DiabetesPedigreeFunction : 가족력
- Age : 나이
- Diabetes : 당뇨병이면 1, 당뇨병이아니면 0
-
File
- data.csv : 당뇨병 데이터 + 당뇨병 보유 여부(0 or 1)
- X_test.csv : 당뇨병 보유 여부 외에는 train 데이터와 동일
- submit.csv : submission 파일의 예시
Preparation
-
kaggle install
1
2
3!pip uninstall -y kaggle !pip install --upgrade pip !pip install kaggle==1.5.6 -
API token upload
1
2
3!mkdir -p ~/.kaggle !cp kaggle.json ~/.kaggle/ !chmod 600 ~/.kaggle/kaggle.json -
Import libraries
1
2import numpy as np import pandas as pd
Data Loading
Competition의 Data 탭에서 필요한 데이터를 가져온다.
-
Import dataset from Kaggle
1
2!kaggle competitions download -c 2021-ml-diabetes !unzip 2021-ml-diabetes.zip -
Input data
1
2
3
4
5
6train = pd.read_csv('data.csv') test = pd.read_csv('X_test.csv') X = train.drop(['Pregnancies', 'Diabetes'], axis = 1) test = test.drop('Pregnancies', axis = 1) y = train['Diabetes']data.isna().sum()을 이용하면 결측치를 확인할 수 있다.
Data Modeling
-
Fitting
1
2
3
4
5from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis qda = QuadraticDiscriminantAnalysis() qda.fit(X, y) pred = qda.predict(test) -
Submission
1
2submit = pd.read_csv('submit.csv') submit['Diabetes'] = pred1
submit.to_csv('submit.csv',index=False)1
!kaggle competitions submit -c 2021-ml-diabetes -f submit.csv -m "Message"
Result
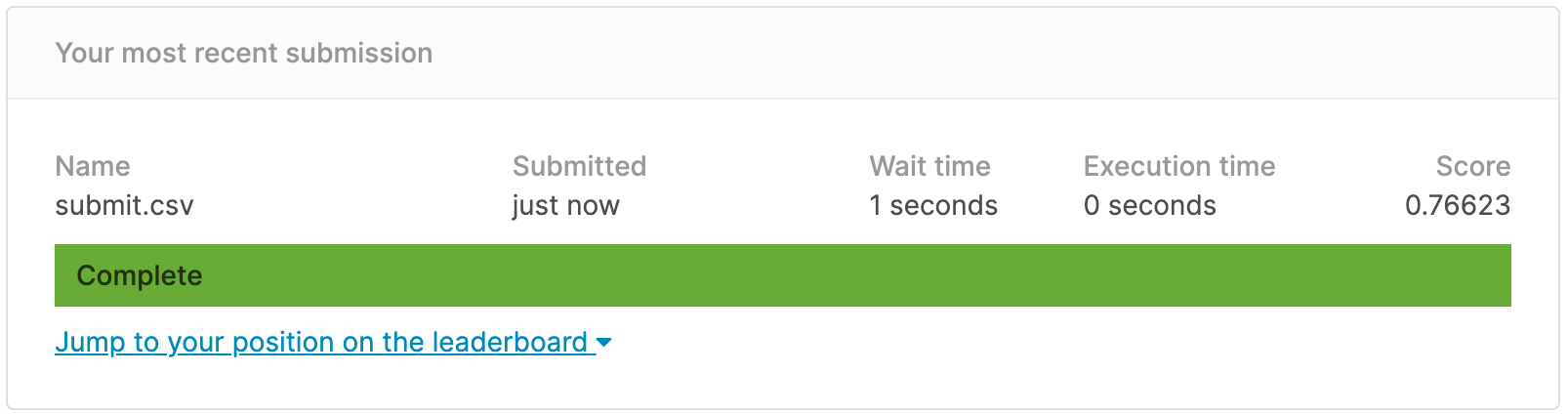
Preprocessing이든 parameter든 열심히 이것 저것 조절해 봤지만 성능이 많이 오르지 않는다.. 해당 문제는 데이터 개수가 그렇게 많지 않아서 scaler에 크게 영향을 받지 않는 것 같다. 데이터가 적을 땐 오히려 scaler에 의해 성능이 떨어질 수도 있으니 적절히 사용하도록 하자!