[ML] ML 프로젝트와 ML 생애주기, MLOps
ML Project
Machine Learning 프로젝트는 단순히 모델을 만드는 것이 전부는 아니다. 데이터를 다루고, 어떻게 학습시켜야 할 지 생각하고, 성능을 향상시키고, 하나의 product로서 배포, 운영하며 모니터링까지 하는 전반적인 과정을 내포하고 있다. 쉽게 이해하자면 다음과 같은 여러 block들로 구성되어 있다.
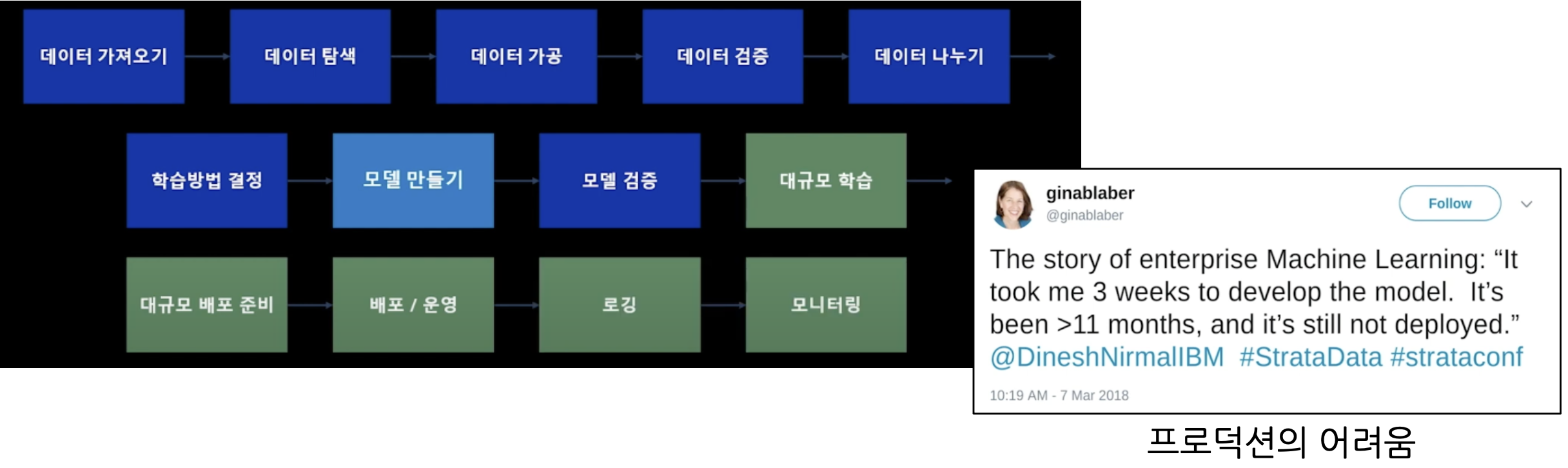
위 사진에서 보이는 모델 만들기 부분을 추후 좀더 심도 있게 탐구하고자 한다.
MLOps
MLOps는 Devops라는 개념에서 발전한 개념이다. MLOps의 역할을 한 마디로 정리하면
내가 만든 Machine Learning model이 Production까지 가는데 큰 도움을 주는 방법론
이라고 볼 수 있다. MLOps는 아래와 같이 6단계로 나눌 수 있다.
- 문제 정의
- 필요 Data 정의, 수집
- model 설계
- model을 통한 service 운영
- 지속적인 service monitoring
- model 재 학습 및 재 배포
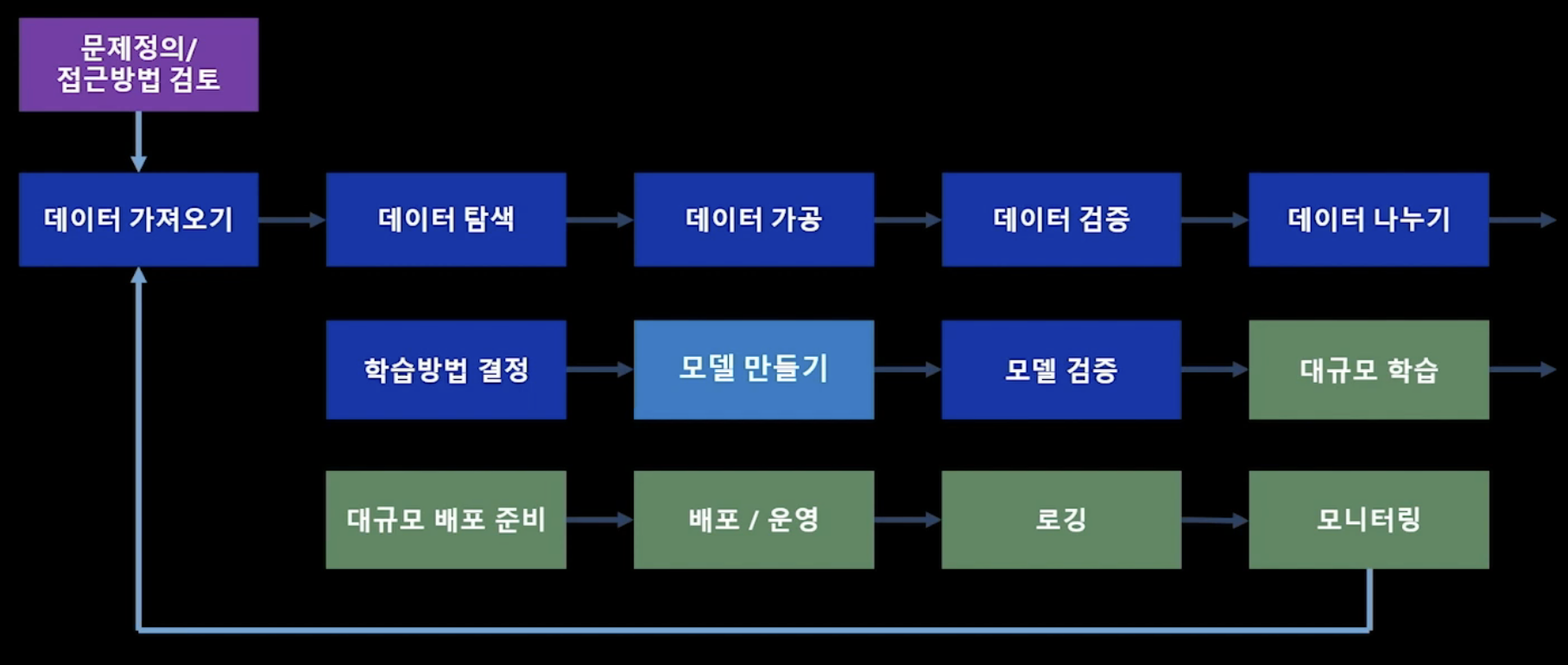
MLOps 담당자
MLOps의 담당자는 크게 전반부 Data Scientist, 후반부 Data/SW Engineer 로 나눌 수 있다.
- Data Scientist
- 빠르게 실험 반복
- ML/DL 프레임워크 사용 (Open lib API)
- 머리 아픈 관리는 최소화
- 대용량데이터(Bigdata) 가공
- Model 학습
- Data/Software Engineers
- Tool/Platform의 재사용. (잘 사용할 줄 알아야한다)
- 전사 정책 (Compliance)
- 모니터링/감사 (Audit)
- 죽지 않고 살아남기 (Uptime)
DevOps vs MLOps
DevOps 개발된 코드의 컴파일, 테스트, 배포의 전반적 SW 생애주기
MLOps 모델 제작, 예측 수행, 서비스 패키징, 배포의 전반적 ML 생애주기
-
공통점
- code 구현, 통합 test
- 운영 배포, monitoring
- feedback을 통한 절차 반복
-
차별점
- model을 만드는 과정과 배포하는 과정으로 구성됨
- code와 data가 함께 필요
기존에는 code만 있었다면, 이제 코드와 데이터가 공존한다.
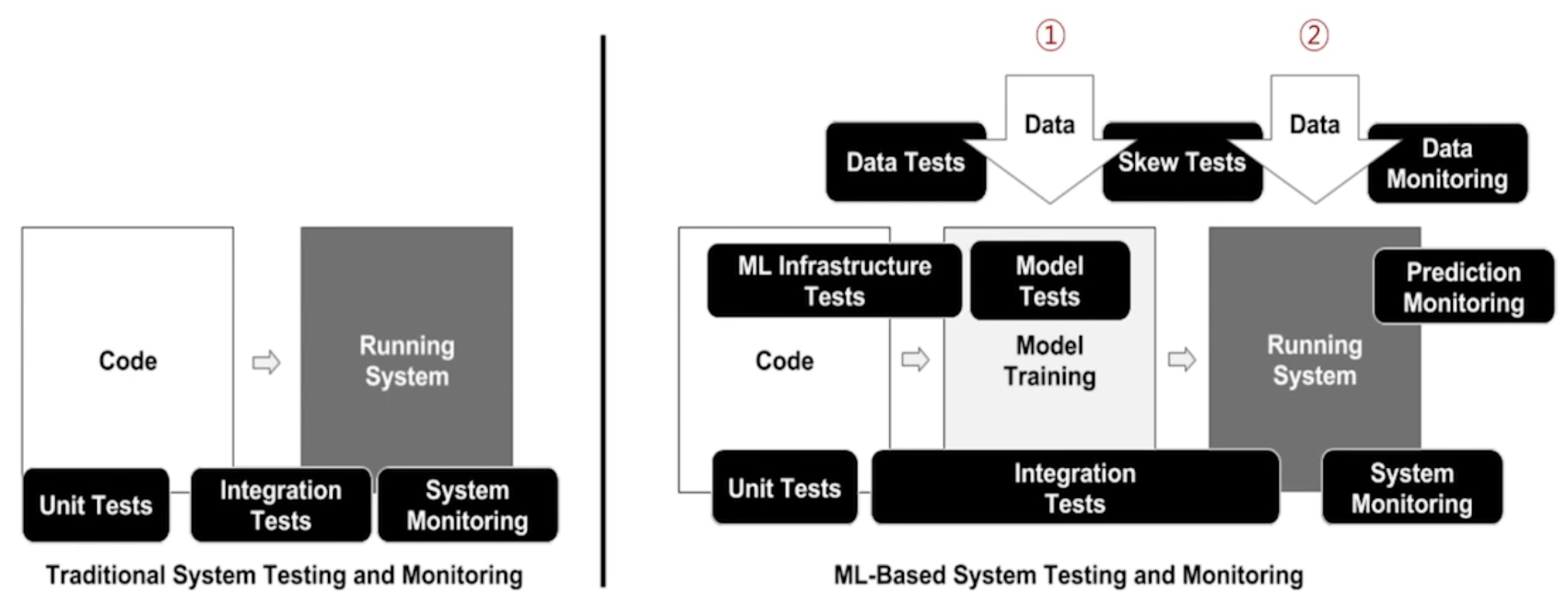
결국 우리는 이렇게 정의할 수 있다. MLOps = ML + DEV + OPS !
MLOps 존재이유
그렇다면 우리는 MLOps를 왜 사용할까?
답은 우리가 만든 model의 성공적인 배포 서비스를 위해 도와주기 때문이다. 이는 학문적인 내용을 떠나 현업과 직결된다는 뜻이다. 앞서 설명했던 Data Scientist 들은 ML을 Production data와 연계하고 지속적인 재학습/재배포 자동화, pipeline을 자동화함으로써 본인의 Algorithm이 본 Service에 자연스럽게 서빙되도록 MLOps를 적용할 수 있다. 또한 Data/SW Engineer 의 경우, 기존에 품질 관리를 위해 사용하던 DevOps 를 ML에도 적용함으로써 ML process의 수준을 향상시킬 수 있기 때문이다.
아래는 MLOps Framework, 파트별 세부 모듈을 나타낸 자료이다.
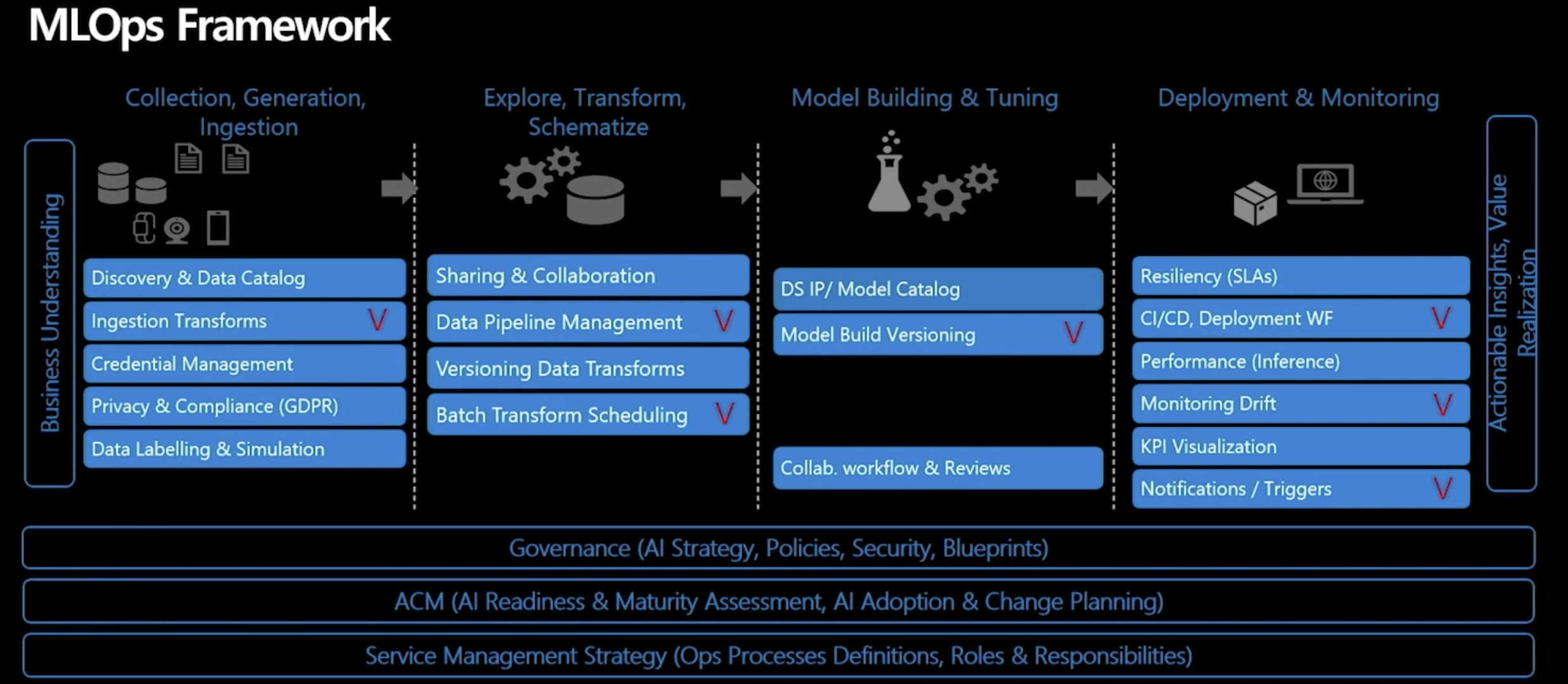
파트 별로 하나하나 세부적으로 뜯어보기에는 아직 세부 내용이 많이 어려운 것 같다. 억지로 머리에 집어 넣기보다 열심히 공부해서 체득할 수 있도록 노력하는 게 제일 중요할 것 같다.
Data preparation
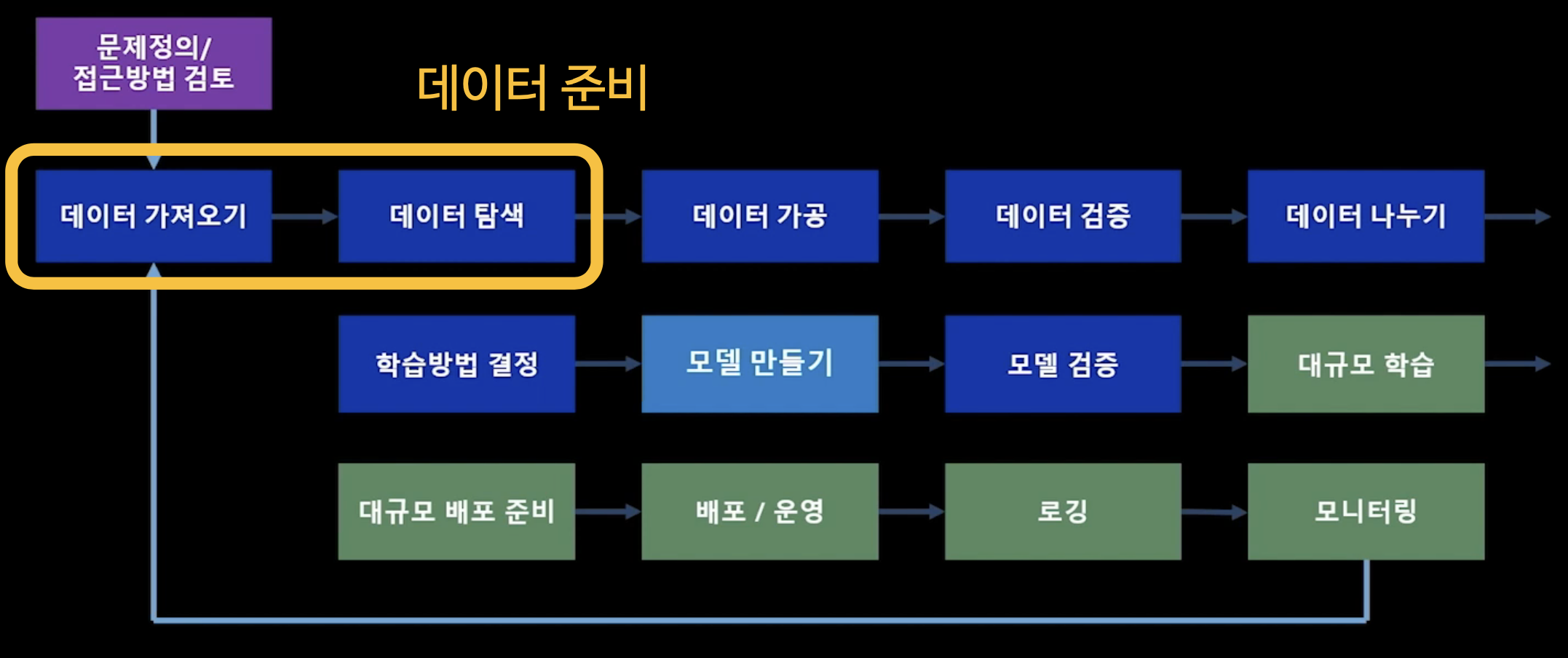
데이터 준비
앞서 살펴본 ML 생애주기 사진에서 데이터 가져오기, 데이터 탐색 부분에 해당하는 단계이다.
-
문제 정의
-
ML도입으로 해결할 문제 정의
어떤 부분에 도입하면 cost를 줄일 수 있을까? 고객 만족도를 높일 수 있을까?
-
문제에 따른 가설 설정 필요
가설 설정에 따라서 가설 검증을 할거고, 이를 위해 모아야 할 데이터셋이 바뀐다. 예를 들어 배추값 예측이면 결정요인이 평균온도, 최대온도, 최고온도, 강우량 등이 있을 거다. 이런 data를 다 모아둔 뒤, 선별하여 몇 가지만 분석해서 예측하는 정확도와 모두 포함해서 예측하는 정확도 등을 비교함으로써 성능 분석이 가능해진다.
-
가설 검증을 위한 dataset 확보
-
-
Business Impact 고려
- 돈 버는 ML project 로 확장되어 가치를 부여받을 수 있다.
데이터 가져오기
- 데이터 확보
- File server, Big data cluster, Relational DB, Cloud Storage 등에 저장
- 데이터 수집
- Real time 데이터를 DB server에 보관 (Raw)
- 데이터 연계 (중요)
- Model 학습을 위해 데이터 형태에 따른 준비과정 (정리, 가공)
- Table data → SQL query, Excel vlookup
- Image → 이미지 종류에 따라 나누는 것
-
데이터 셋 공유 및 재사용
-
Version Control의 필요성
Dataset이 문제 정의에 따라 다양하게 가공되어 사용 가능하다. 또한 데이터 셋이 추가되어 별도의 관리가 필요하다. git을 통한 version control을 사용하듯, 주로 Microsoft Azure를 사용한다.
-
데이터 탐색/가공
-
데이터 탐색
- python, R 등 data visualization을 위한 다양한 package 이용 가능
- 데이터 탐색을 위한 visualization 방식 고민이 필요
-
데이터 Labeling (중요)
-
task의 목적에 맞는 정답을 수동으로 제공하는 과정
tag 달기(카테고리 지정), box 그리기, segmentation label 등
-
-
Feature 중요도 탐색
-
데이터로 제공되는 속성 중 문제 해결에 영향을 크게 미치는 것을 찾는 과정
예를 들어 성인 인구조사 소득 이진 분류 dataset이 있다면, 여러 요소 중 어떤 속성이 고소득자와 관련이 깊은지 탐색하는 과정이다. (성별, 나이, 학력, 등등..)
-
Experiment/Learning
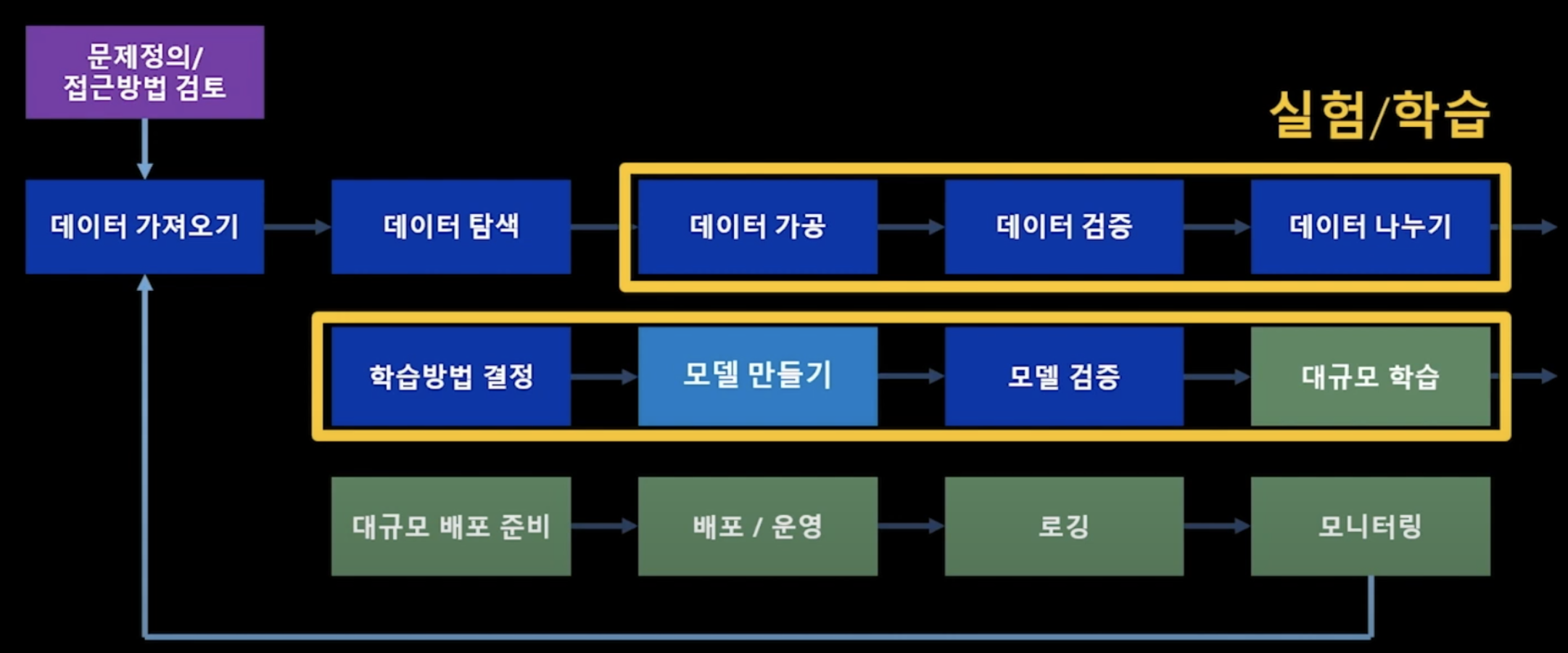
- 학습의 목적
데이터 전처리를 포함하여, 데이터를 어떻게 가공하느냐는 모델의 성능을 좌우하는 중요한 부분이다. 또한 모델을 만드는 것은 실험/학습 파트의 핵심이라고 볼 수 있다. 학습의 목적은 결국 모델을 만드는 것이다.
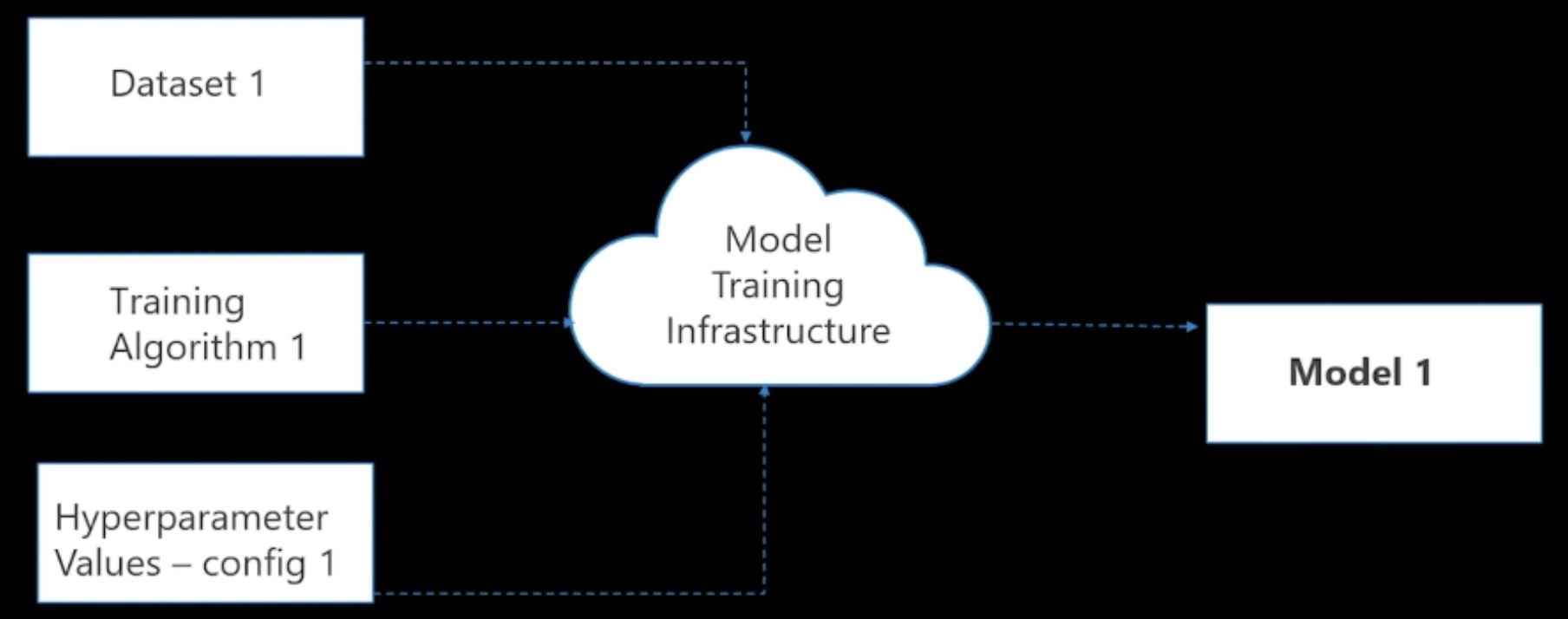
Model Data/Algorithm/Paramete 를 가지고 연산을 거쳐 만들어지는 산출물
- 모델 학습을 위한 입력 조건
- Data
- Algorithm (Input data의 pattern 찾기)
- Hyper-Parameter (최대 성능을 내기 위한 Algorithm의 속성)
- 실험의 목적
학습의 목적이 모델을 만드는 것이라면, 실험의 목적은 다양한 실험을 통해 최적의 모델을 찾아가는 것이다.
실험 입력 조건(Data/Algorithm/Hyperparameter)을 바꾸는 과정
최적의 모델 만족할만한 성능을 제공하는 모델
- 최적화
최적화란, 문제 해결을 위해 모든 경우의 수를 탐색하지 않고, 최적화된 방법(Optimal)으로 입력 조건을 찾는 것이다. 일반적으로 기존 연구 결과를 참고하거나 개인의 노하우를 활용한다. 확실히 모든 경우의 수를 다 실험하는 것은 비효율적이므로, 일반적인 방법으로는 논문을 참고하거나 대략적 실험 setting을 따라할 수 있다.
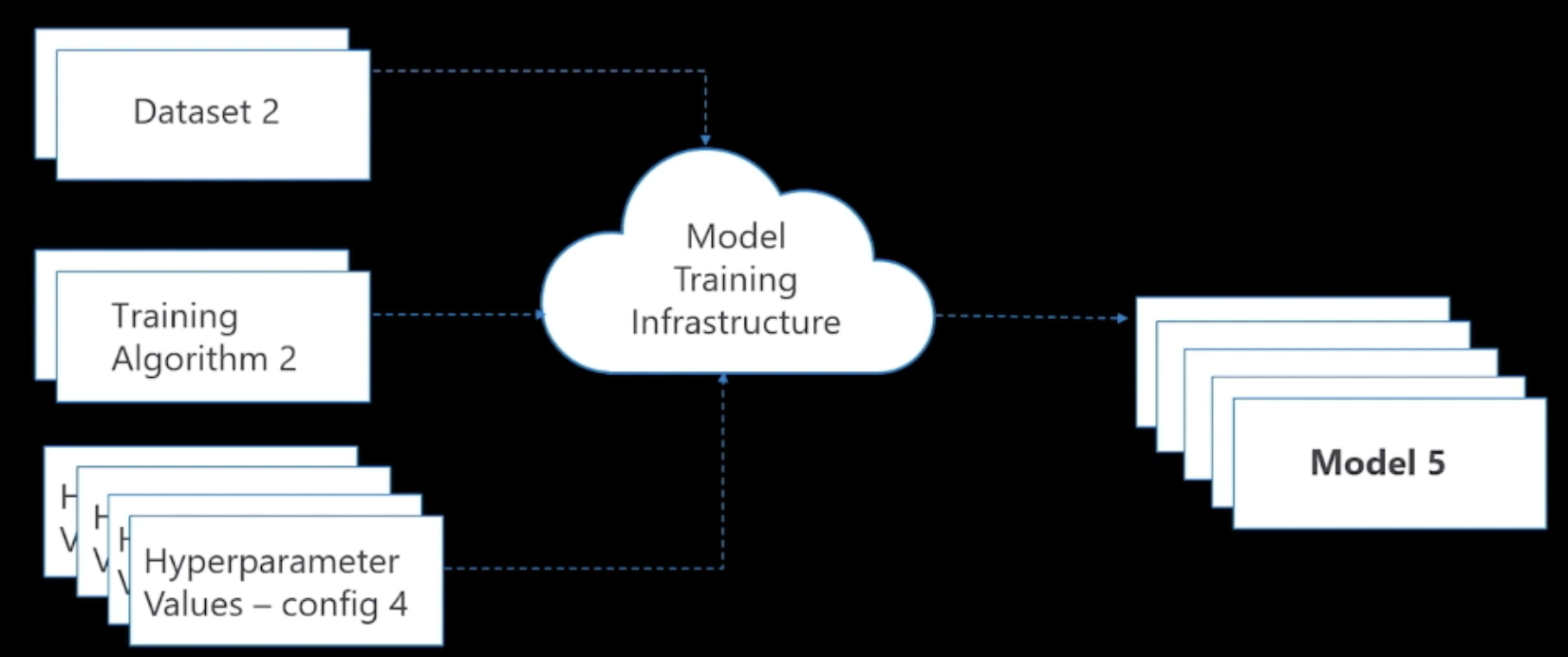
모델 검증
- 비교 평가
-
다양한 모델에 따른 성능 비교
-
다양한 모델의 학습 조건 비교
학습 조건 모델 학습에 사용한 Data/Algorithm/Hyperparameter 를 의미
- 실험 추적 관리 (중요)
- 최적 모델 선정을 위한 비교평가는 모든 조건을 기록할 필요가 있다.
-
실험 조건 관리
code/data version, package version 관리 (meta info), 구체적이어야 함
-
모델 관리
실험 수행을 통해 획득된 다수 모델 버전 관리. 가장 좋은 모델 정보 (성능 지표)
-
실제로 성능을 최대한 뽑기 위해 동시다발적으로 여러 실험을 한다. 이때 메타정보가 관리되지 않으면 차후 설명이나 재현이 어렵다.
학습 방법 결정
자동화된 ML(AML, Automated ML)은 빠르게 최적 모델을 찾는 지능화된 학습 방법이다. 모든 경우의 수를 실험해보는 것이 아닌, 입력 조건에 따른 ML 파이프라인 성능을 예측하여, 성능이 좋을 것으로 예상되는 입력조건을 통해 모델 학습을 자동으로 진행하는 방법이다.
개발자가 직접 데이터의 전처리 방법과 algorithm의 hyperparameter를 변경하면서 실험하는 것이 불필요함
모델 검증
모델을 검증하는 과정에서는 해당 모델의 성능을 예측 성능과 처리 성능으로 구분한다.
-
예측 성능: 개별적 모델의 성능을 분류/회귀 등 관련 평가지표로 확인
Data Scientist의 관심사
-
처리 성능: 서비스 배포 후 얼마나 안정적으로 운영되고 있는지 확인
Data Engineer의 관심사
Deployment / Serving
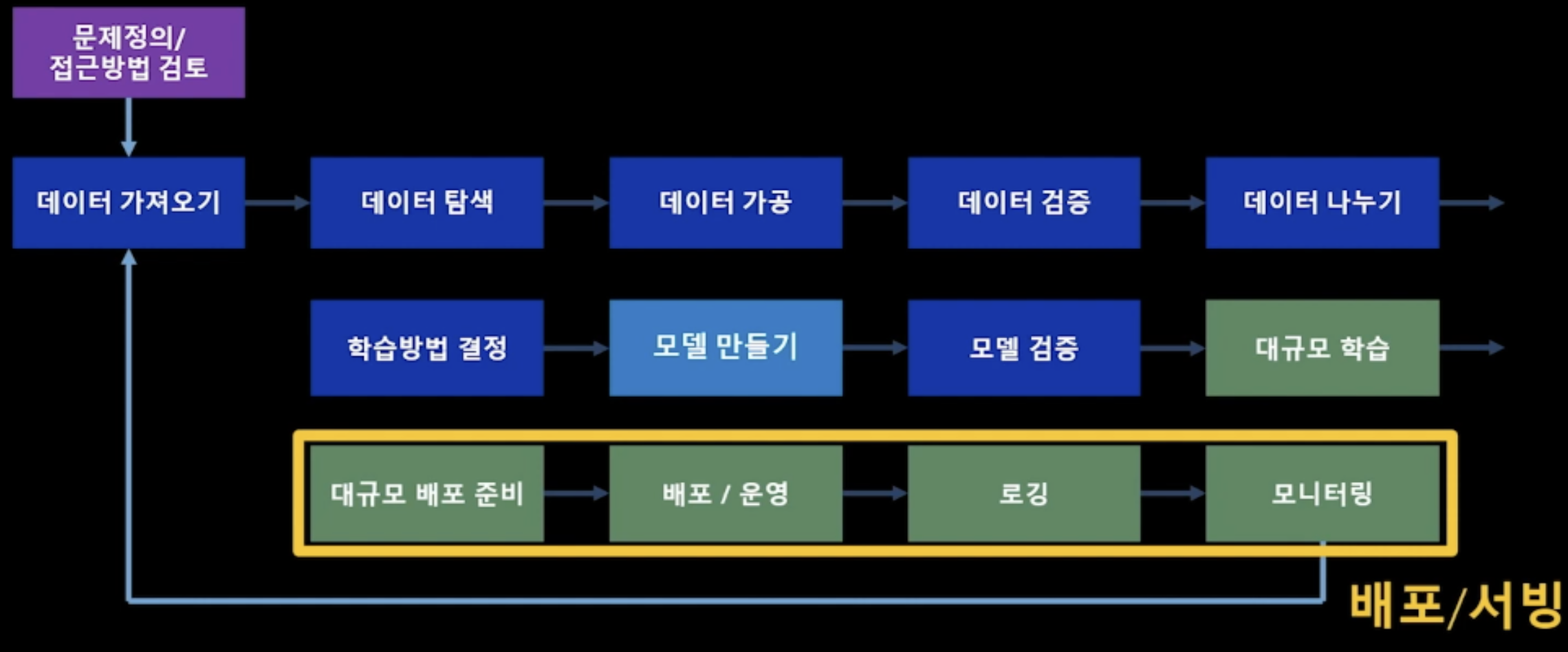
배포/서빙이란, 가장 좋은 모델을 선택하고 검증 과정을 거친 뒤, 각종 개발환경을 하나로 묶어(packaging) 하여 서비스로 배포하는 일련의 과정이다. 다양한 Open library를 사용하는 ML의 특수성 때문에 배포가 쉽지는 않다. 많은 사람들이 고민했고, 최근에 docker라는 가상화 기술이 등장했다. Docker는 package의 이미지화를 통해 어떤 공간에 있든 상관없이 동일한 환경에서 모델이 동작할 수 있도록 해준다고 한다. 기회가 되면 Docker에 대해서도 알아보고 포스팅하겠다.
-
대규모 배포준비 (Packaging)
-
컨테이너(이미지) 제작 기술
컨테이너 기술 모델 학습환경/예측환경을 동일하게 맞추기 위해 필요
-
모델 버전, 패키지 버전, 추론 로직. 모든 환경을 다 맞춤
-
-
배포/운영 (Serving)
-
컨테이너를 서버에서 실행하여 서비스 운영
ex) 컨테이너에 웹 API 방식의 서버가 올라가 있음 → 실시간으로 입력 데이터가 들어옴 → 입력 데이터를 이용하여 모델 예측 값을 계산 → 예측된 결과 반환
-
Rest API를 통해 접근 가능
-
-
모니터링 (Data Drift)
- 데이터 패턴 특성이 시간이 지나며 변하는 현상
- 학습 데이터, 예측 데이터의 차이(패턴, 분포)가 커질수록 예측 성능 저하 가능성
- 지속적으로 데이터 드리프트를 모니터링하며 모델의 재 학습 시점 판단
MLOps in Action
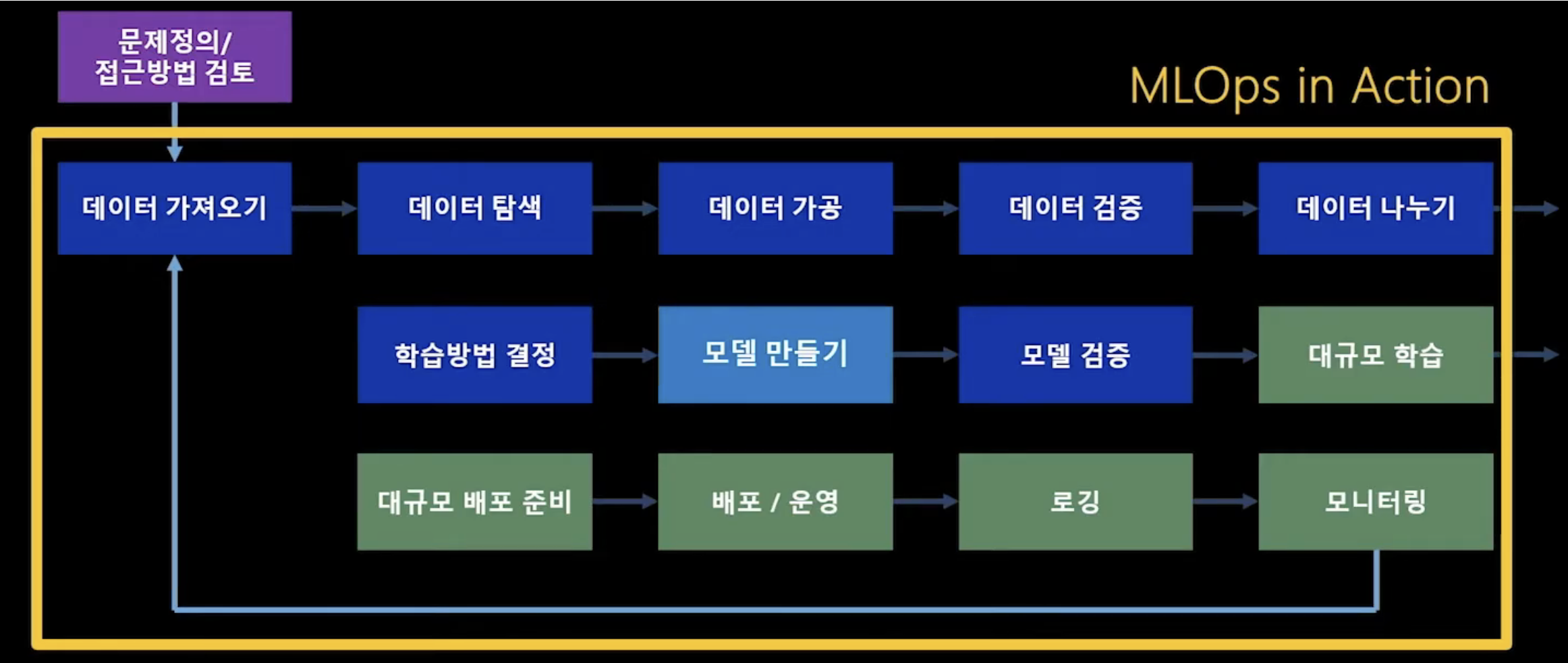
- 데이터 가져오는 파이프라인
- 모델 생성
- 모델 평가
- 서비스 패키징
- 서비스 배포
- 서비스 모니터링
결국 MLOps를 적절히 잘 활용하면 기존 서비스의 서버를 shutdown 하지 않고, 더 좋은 모델이 개발되면 새로운 모델이 자동으로 등록, 패키징, 배포되도록 하는 일련의 과정이 가능해진다. 이러한 MLOps를 가능하게 하는 cloud 기반 framework에는 대표적으로 Amazon AWS, Microsoft Azure, Google GCP 가 있다. MS Azure 는 Machine Learning Tool 30일 평가판도 있으니 참고해서 직접 사용해보는 것도 좋을 것 같다.
나는 아직 학부생 3학년 신분으로, 내가 어떤 파트를 집중적으로 파고들어야 할지 확신은 서지 못했지만 최근에는 Machine Learning / Deep Learning을 활용한 Audio Processing에 관심이 생기기 시작했다. 앞으로 더 세부적인 공부를 해나가며 관심이 가는 분야 관련 기술 stack을 끊임 없이 찾고 공부해나가고자 한다.