Rich feature hierarchies for accurate object detection and semantic segmentation
R-CNN 논문인데 왜 Rich Feature Hierarchies 인가
- Rich Features (풍부한 특징)
- 코세라에서도 이야기하듯, CNN은 이미지를 입력으로 받아 여러 계층(layer)을 거치면서 점점 더 추상적인 특징을 추출
- 초기 계층에서는 단순한 edge나 코너 같은 저수준(low-level) 특징들을 추출하고, 이후 계층으로 갈수록 더 복잡한 패턴, 객체의 일부분, 그리고 최종적으로는 전체 객체와 같은 고수준(high-level) 특징들을 추출 (Audio, NLP 등의 예시와 비슷)
- “Rich”는 여기서 CNN이 다양한 수준에서 매우 풍부하고 다양한 정보를 추출할 수 있음을 의미
- Feature Hierarchies (특징 계층 구조)
- CNN의 계층 구조는 저수준 특징에서 시작해 고수준 특징으로 발전하는 일종의 계층적 구조를 형성
- 이 계층 구조를 통해 모델은 간단한 시각적 패턴부터 복잡한 객체까지 다양한 수준의 정보를 포착
- 따라서 복잡한 이미지 인식 작업에서도 높은 성능 발휘
- 각 계층이 서로 다른 수준의 정보를 처리하고, 이 정보들이 결합되어 최종 예측
“Rich feature hierarchies” → R-CNN이 CNN을 활용해 객체 검출과 같은 작업에서 매우 풍부하고 복잡한 특징들을 다룰 수 있음을 강조하는 표현
Abstract
그동안 PASCAL VOC 데이터셋에서의 Object Detection은 여러 개의 low-level 이미지 특징들과 high-level context를 결합하는 앙상블 방식을 통해 가장 높은 성능을 보였다. 이 논문은 단순하고 확장 가능한 알고리즘을 통해 mAP(mean average precision)을 30% 향상시켰으며 두 가지 핵심 인사이트는 다음과 같다.
- 객체의 위치를 찾고 분리하기 위해 bottom-up 방식의 region proposal에 CNN을 적용하였다.
- 라벨링이 된 데이터가 부족할 때, supervised pre-training에 이은 domain-specific fine-tuning 성능을 크게 향상시켰다
1. Introduction
object detection 분야의 기술은 최근 몇 년간 큰 진전이 없었다.
- 지금까지 다양한 image recognition 과제에서 SIFT와 HOG가 중요한 역할을 했음.
- PASCAL VOC object detection 성능은 2010-2012년 동안 큰 발전이 없었고, 앙상블 시스템과 기존 방법의 변형을 통해서만 소폭의 성능 향상이 있었음.
- SIFT와 HOG는 단순한 블록 기반의 방향 히스토그램(blockwise orientation histograms)
- 그러나 인식 과정은 더 복잡한 단계들을 통해 이루어지며, 더 유익한 계층적 다단계 특징이 필요할 수 있음.
- CNN은 이러한 계층적 특징 추출에 적합한 모델로, 초기의 neocognitron 모델을 발전시킨 형태. LeCun 등이 CNN을 효과적으로 훈련할 수 있는 방법을 제시했지만, 1990년대 이후 SVM의 대두로 CNN의 인기가 줄어들었음.
CNN을 object detection에도 사용해보고자 한다.
- 2012년에 Krizhevsky 등이 ImageNet 대회에서 CNN을 활용하여 높은 이미지 분류 정확도를 보여주면서 CNN에 대한 관심이 다시 높아짐.
- 이 논문에서는 CNN을 객체 검출에 적용하여, PASCAL VOC에서 기존 HOG 기반 시스템보다 훨씬 높은 성능을 달성할 수 있음을 처음으로 보여줌.
두 가지 문제점이 있었다.
- **Localizing objects with a deep network **[이미지 분류와 달리 객체의 위치도 정확히 찾아야 함]
- regression 문제로 localizing을 진행하는 방법→ 실용성이 부족
- sliding-window detector 설계→ network에서 large receptive field을 가져 잘 사용하지 않음
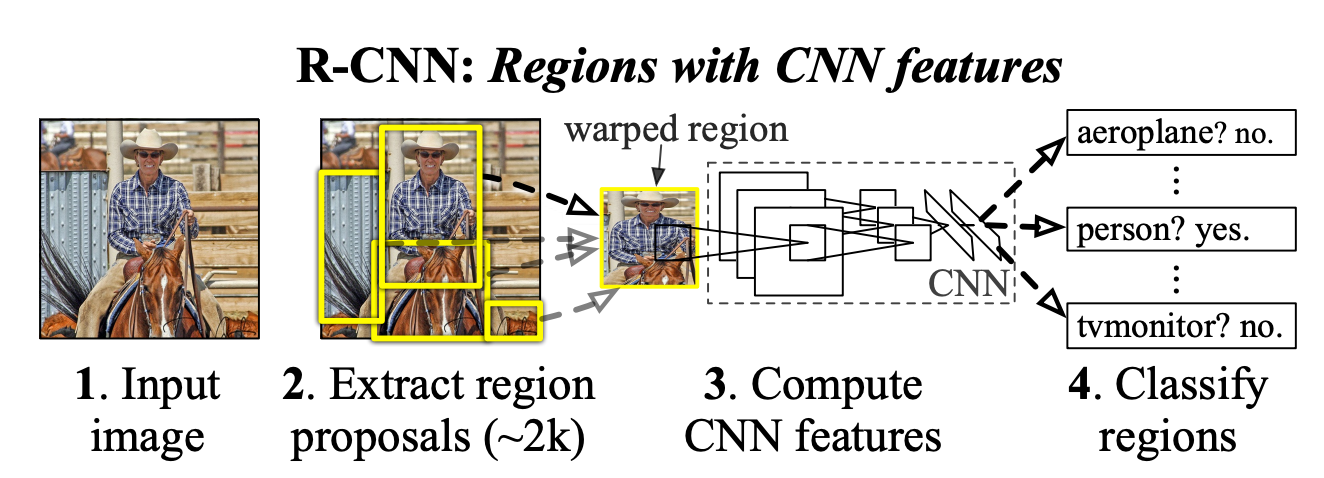
- Recognition using regions→ 이 방법을 논문에서는 추천
- 2000개의 독립적인 region proposal을 input image에서 추출
- 각각의 proposal에서 정해진 길이의 feature vector를 CNN을 통해 추출
- 각 카테고리마다 다른 linear SVM으로 region을 classify. 이때, image warping을 이용해서 CNN의 input을 일정하게 고정
- R-CNN이라 명명
- R-CNN은 ILSVRC2013 검출 데이터셋에서 OverFeat보다 우수한 성능을 보였음.
- Training a high-capacity model with only a small quantity of annotated detection data [데이터의 부족]
- supervised pre-training을 사용해 나중에 fine-tuning을 진행
- AlextNet으로 pre-training 된 모델 사용 가능
2. Object detection with R-CNN
- R-CNN은 크게 세 단계(모듈)로 구성된다.
- category - independent region proposals
- large convolution neural network
- class specific linear SVMs
2.1 Module design
Region proposals
-
Selective Search

-
segmentation 분야에서 널리 쓰이는 알고리즘
-
color, texture, size, fill(유사한 주변과의 차이 정도) 4가지 특징을 사용해 유사도가 높은 공간끼리 merge 하며 bottom-up 방식으로 2000개의 Region proposals를 만들어 냄
-
처음에는 Random하게 많은 Bounding box들을 생성한 뒤 점점 합쳐나가면서 물체가 위치할 가능성이 높은 영역을 식별
-
Selective Search for Object Recognition
-
NMS (Non maximun Suppression)

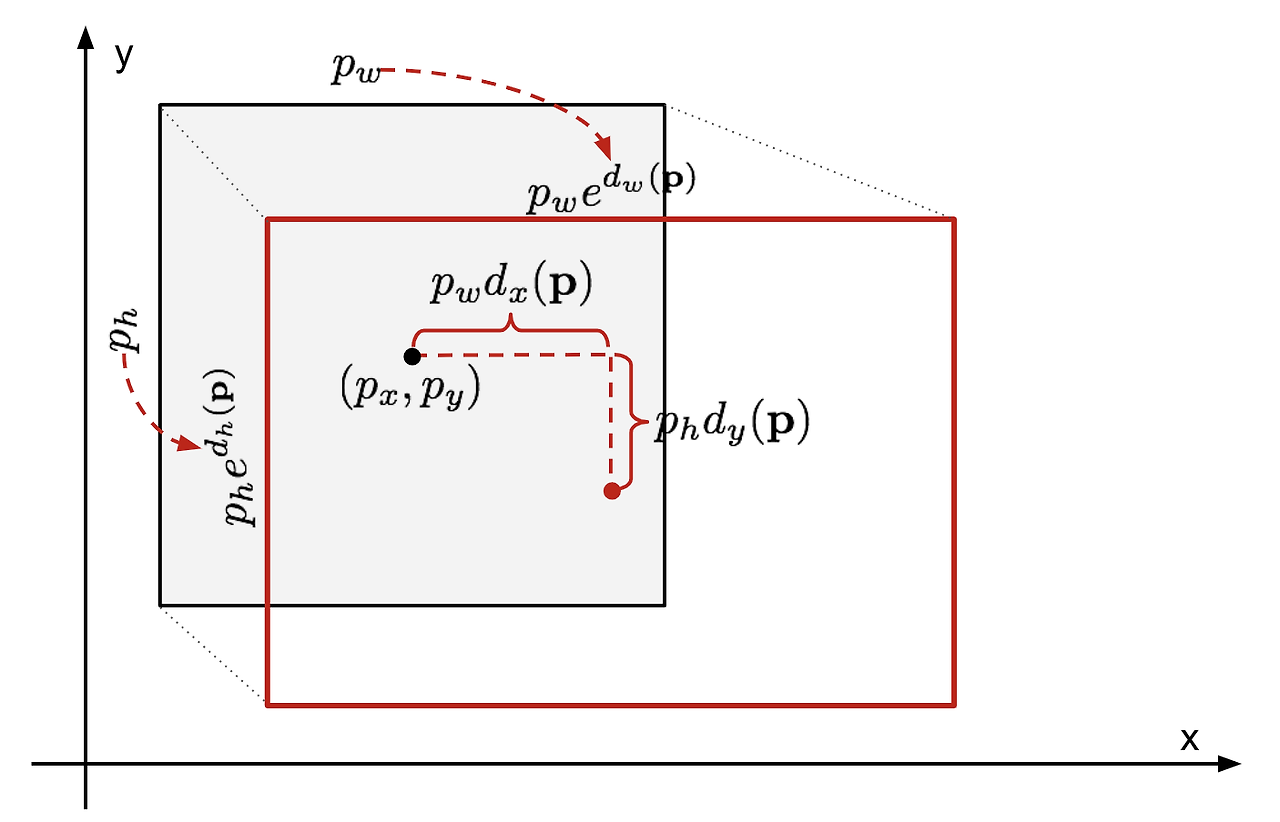
BBR (Bounding Box Regression)
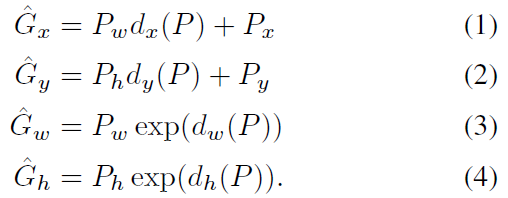
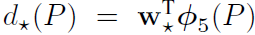
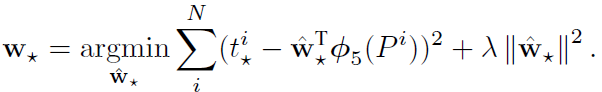
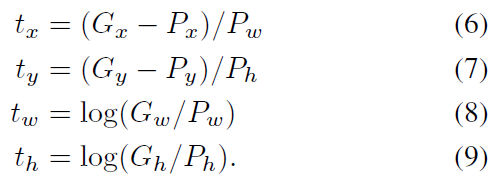
-
Bounding box regression의 경우 모든 output bounding box에 대해서 진행할 필요가 없으며, R-CNN에서는 ground truth box와 predict box와의 IoU가 0.6 이상인 값에 대해서만 진행
Feature extraction

- Fine tuned AlexNet을 사용하여 각각의 region proposal에 대해 4096 dimensional feature vector 추출
- 5 convoutional layer & 2 fully connected layer
- CNN의 input size가 227*227이어야 하므로, 각 region proposal의 사이즈를 변경해줘야 함 (Warp)
- 약간 확대 후 p=16으로 bounding box 제거
2.2. Test-time detection
- selective search의 fast mode로 2000개의 region proposals 추출
- 각각의 region을 warp한 후 CNN에 입력하여 feature 추출
- 추출한 feature vector 를 각각의 class 하나에 대해 학습되어 있는 SVM에 넣어 scoring
- greedy non-maximum suppression 방법을 적용
- 모든 region에 대해, 점수가 더 높은 region과의 IoU(겹치는 부분)이 특정 threshold를 넘으면 해당 region을 제거하는 방법
Run-time analysis
- R-CNN은 CNN parameter들이 모든 category에서 공유됨
- 해야 할 계산이 selective search, 그리고 SVM에서의 간단한 single matrix - matrix product 밖에 없다.
- 계산량이 적어 빠른 추론이 가능하고 효율적이며, 대부분의 CPU에서 빠르게 수행될 수 있다.
2.3. Training
Supervised pre-training
-
ILSVRC2012 classification
-
CNN 자체는 Krizhevsky의 성능과 거의 일치
- A. Krizhevsky, I. Sutskever, and G. Hinton. ImageNet classification with deep convolutional neural networks. In NIPS,
- 1, 3, 4, 7
Domain-specific fine-tuning
- CNN을 detection이라는 새로운 작업과 새로운 도메인 warped VOC windows에 적용시키기 위해 SGD를 이용하여 CNN parameter를 warp 된 region proposal을 이용해서 학습을 진행
- CNN의 ImageNet 특정 1000개 분류 레이어를 무작위로 초기화된 21개 분류 레이어(20개의 VOC 클래스와 배경)로 대체하는 것을 제외하면, CNN 아키텍처는 변경되지 않음
- CNN의 classification layer를 원래 이미지넷 데이터에 맞춰 학습되어 있는 1000-way가 아니라, (N+1)-way의 layer로 바꾸어준 후 학습을 진행 (N은 object class 개수, 여기에 배경을 더하기 위해 +1 해준다.)
- ground truth box와 IoU 오버랩이 0.5 이상인 region proposal만 positive로 여기고, 나머지는 negative
- LR = 0.001 SGD 이용, 32개의 positive windows와 96개의 background windows 총 128 개의 batch size로 학습
- positive window는 background에 비해 매우 드물기 때문에 sampling을 positive window를 향하도록 편향
Object category classifiers
- SVM에서 만약 car의 일부분이 overlap 되어 있다면 label을 어떻게 할 것인가?
- 물체가 부분적으로 들어가 있는 region을 해결하기 위해 IoU overlap threshold를 정하고, 그 임계값을 넘는 region만 positive로 사용 → threshold 값을 잘 정하는 것이 중요
- grid search를 이용해 찾은 최적의 IoU 임계값은 0.3 (0, 0.1, …, 0.5)
- feature 추출과 training label 부여를 마친 후에는 linear SVM을 최적화
- hard negative mining method를 통해 빠르게 수렴하는 방식을 채택
2.4. Results on PASCAL VOC 2010-12
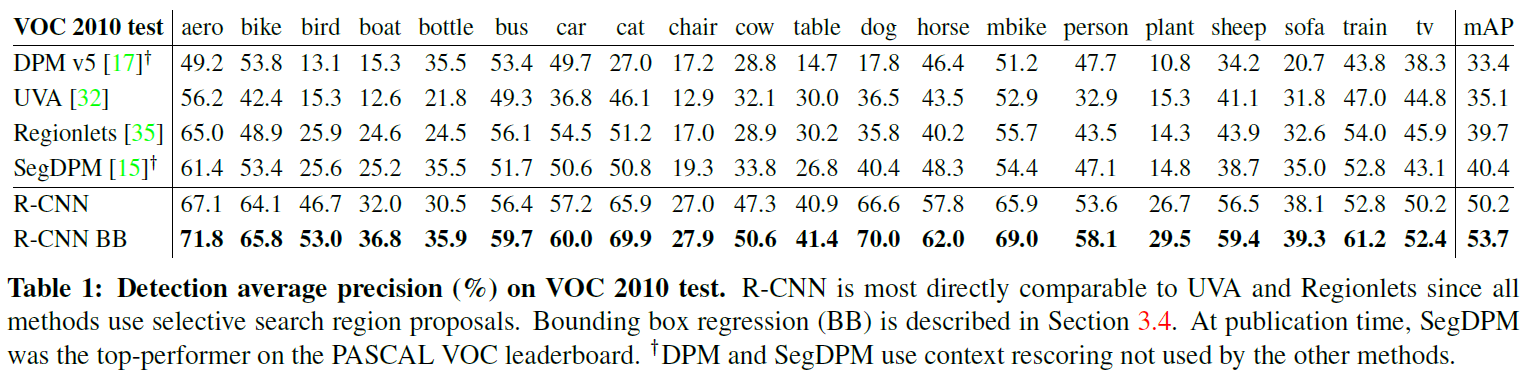
- PASCAL VOC : 20개 class에 대해 object detection을 수행하기 위한 데이터셋.
- 기존 최고 성능인 35.1%에서, mAP가 53.3%까지 상승하는 좋은 성능을 냄
- 같은 region proposal 알고리즘을 사용하는 다른 방법에 비해서도 CNN을 추가한 R-CNN의 성능이 우수
- Bounding box regression을 추가하였을 때, 그렇지 않은 경우보다 성능이 더 높게 나옴. (appendix C에서 설명)
2.5. Results on ILSVRC2013 detection
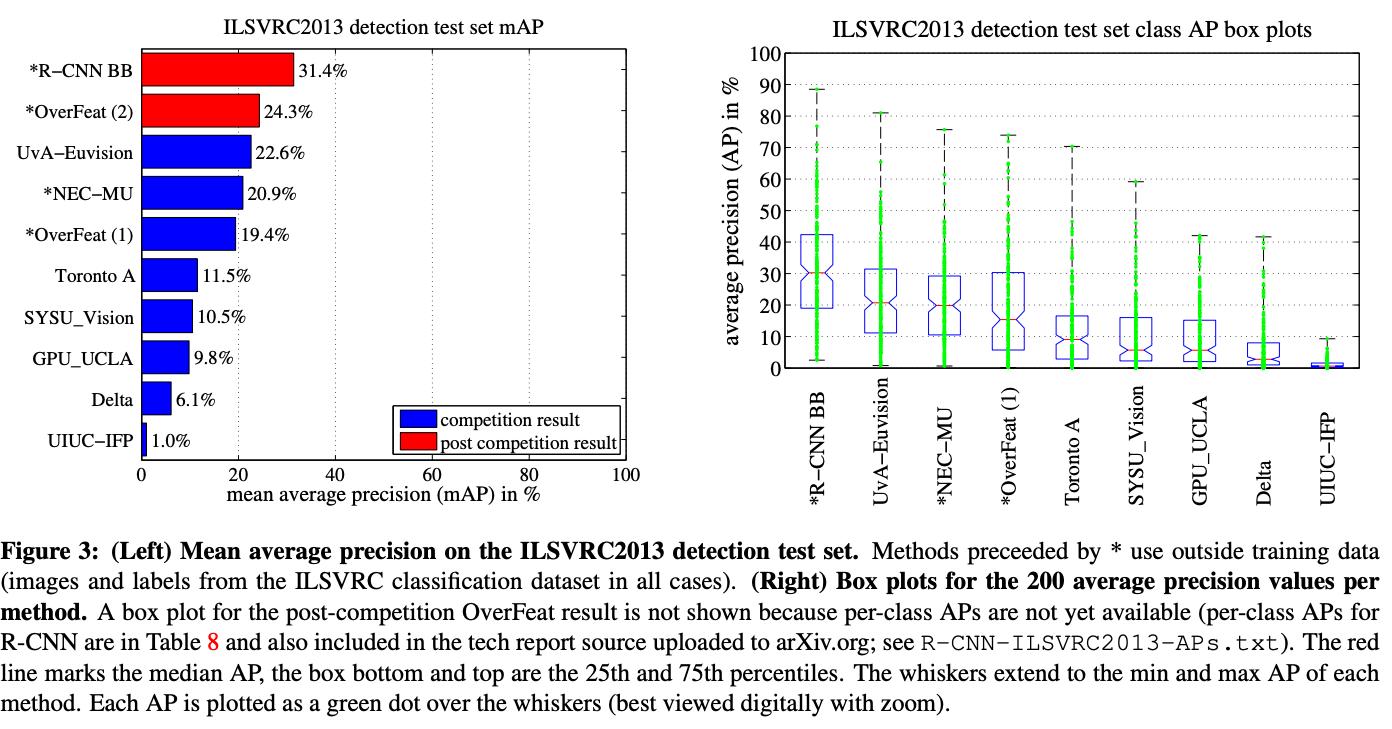
- 200개의 class에 대한 detection을 수행
- 24.3% mAP가 가장 좋은 성능이었으나, R-CNN을 사용했을때에는 31.4%로 좋은 성능을 냄.